
The Machine Beat the Professors. Or Did It?

A student emails you at eleven at night. She is understandably confused about UCC 2-207 — the battle of the forms, the part of first-year Contracts that has reduced stronger minds than hers to despair. You have a faculty meeting in the morning, two sets of comments due, and concern about evaluations from Gen-Z students unaccustomed to latency. You write her four sentences. They are correct, they are fast, and they are nothing like the answer you would give if you had an afternoon and your own notes in front of you. They are the answer she actually gets. Multiply that by every quick question every student asks across a semester, and you have described most of the doctrinal tutoring that happens in a law school — not the seminar, not the cold call, but the harried clarification delivered in the cracks of a working day. That is the thing nobody studies, because it is too ordinary to study. Until now somebody did.
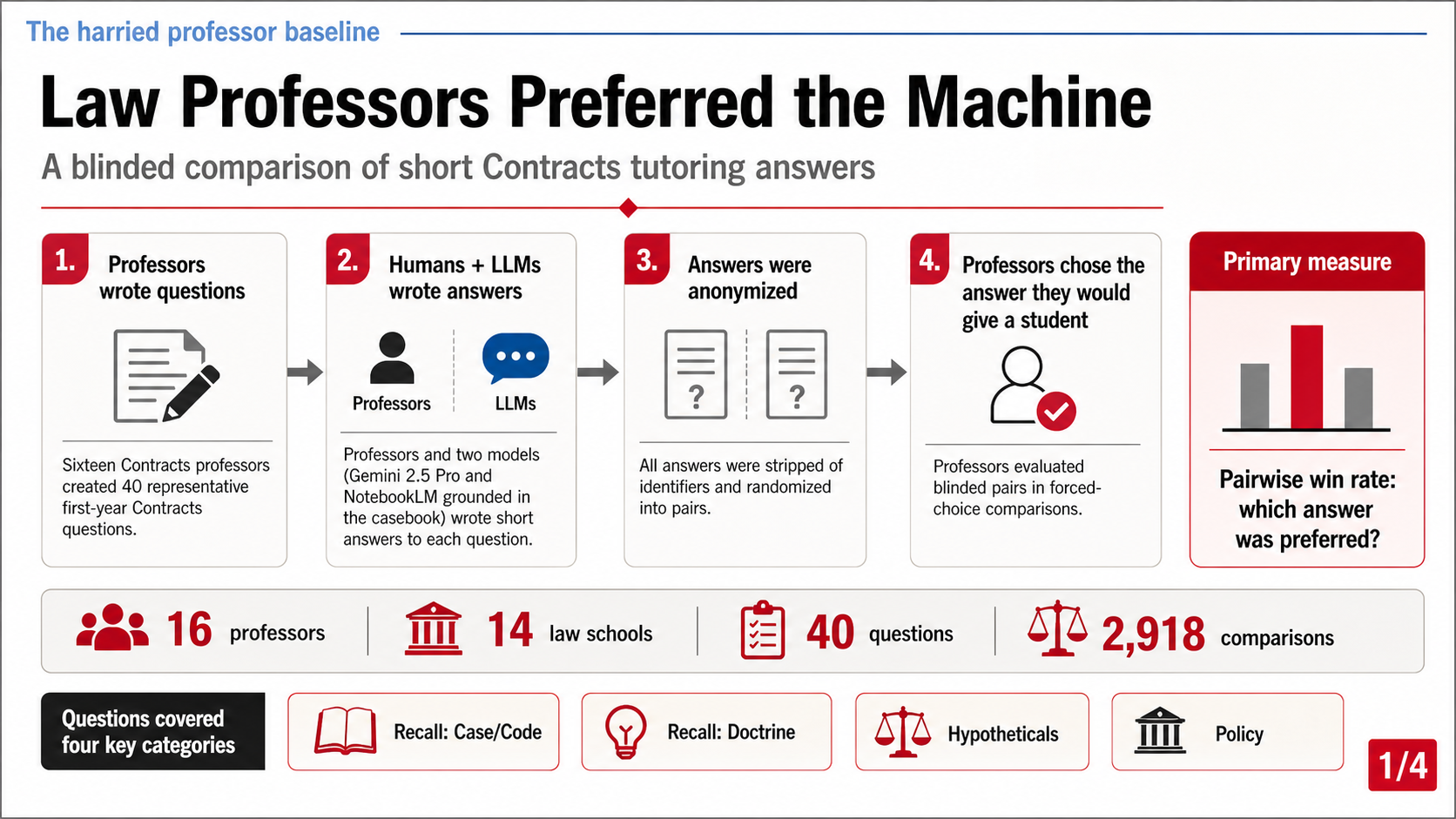
The study is Law Professors Prefer AI Over Peer Answers, by Alejandro Salinas, Julian Nyarko, and a long roster of co-authors that includes Ian Ayres, Omri Ben-Shahar, Gregory Klass, and a dozen other heavyweight professors. Sixteen of them, drawn from fourteen schools, all teaching from the same casebook. They wrote forty representative office-hours questions, answered ones they did not write, and then — blinded, not knowing which answer was whose — judged 2,918 head-to-head comparisons between a colleague’s answer and a machine’s. Gemini 2.5 Pro won 75.92% of its matchups against the humans in this giant tournament. NotebookLM, grounded in the actual casebook, won 74.75%. Every single judge, on average, preferred the machine. And the answers the professors flagged as likely to harm a student’s learning ran 12.06% for humans against 3.53% for the models.
Those numbers are real and they are not small. The interesting part is what happened when AI's themselves got hold of the design. I gave the study to three AIs (Claude Opus 4.8, ChatGPT 5.5, and Gemini 3.1). Here's the prompt:
Read through this paper and develop a methodological critique and any valid criticisms of the conclusions drawn by the authors. If you were "deposing" the authors, what questions would you want to ask them? Assuming, however, that the study is valid, what are its implications for legal education? I want an organized report of about 3000 words. Audience is some mixture of data scientists, statisticians, law deans, law students.
They each came back with responses. I then fed the three responses to each of the three models and asked ...
OK. Now here is your critique of the article along with three others. Imagine you are the study authors. You are smart people who thought about at least some of these issues. How do you respond to the critiques. Where are they perhaps harsh or impractical? Where might the critiques have a point. In light of your reflection of these critiques and the original article, what are its implications for legal education? Prepare an organized response of 2500 words.
I then asked Claude (my present favorite for writing) to draft a blog entry in my voice synthesizing the results.
I'm now adding in three rebuttals to the critiques. Write a blog entry for me using my voice (find the right skill) of 3000 words that engages with the study, its legitimate criticisms, and, most importantly, its implications (as appropriately discounted based on valid criticisms) for legal education. when done /belcher-proof the draft blog entry
What you see here is that last effort – but modified through a dialog between Claude and me as well as some old-fashioned by hand edits. Oh, I also fed the blog entry to ChatGPT, which currently has by far the best image model, and asked it to produce visualizations reflecting the blog entry. You see some of its work interspersed here. And I uploaded the conversation to NotebookLM and asked it to create a debate and a video explainer. (I didn't give it the blog entry, though, at that time). Here are the results.
Here's a link to the notebook, if you want to interact with it.
The harried-professor baseline
Start with the objection that every critic raised, because it is the one that matters most. The professors did not write their answers under teaching conditions. They wrote them under a stopwatch. The instructions told them to spend three minutes or less, to do no research, to skip their own slides and notes, and to imagine a line of students waiting and a faculty meeting looming. One critic called it a deliberately induced three-minute panic. Another, less gently, said the study stacks the deck. The machine, meanwhile, composed freely, hit an ideal length the researchers had calibrated from faculty answers, and — in the reasoning model’s case — thought before it spoke. So the comparison is not human expertise against machine expertise. It is a professor’s rushed note against a polished paragraph. Two different production processes wearing the same blind.

That is a strong objection. I think it is also, in its strongest form, wrong — and the authors’ reply is the most important paragraph in this whole exchange.
The realistic counterfactual to the machine’s answer is not the answer you would write with an afternoon. It is the answer the student actually receives. She does not get your researched memo. She never gets it. She gets the four sentences at eleven at night, or she gets nothing, or she gets a commercial outline, or she gets ChatGPT. Measured against that baseline — the marginal unit of instructional support a real student can actually obtain — the three-minute constraint is not a handicap. It is the ecology. The authors did not throttle the professors to flatter the machine; they throttled the professors to measure the thing professors actually deliver. One critic even proposed, as a fix, that the researchers should have throttled the LLM to human typing speed. That gets it exactly backward. The speed is not a confound to be scrubbed out. The speed is the finding. A tool that produces a usable answer in four seconds is educationally different from a professor who produces one in three minutes, and pretending otherwise to achieve laboratory symmetry would measure a system no student will ever touch.
So the baseline survives — but only for a narrow claim. The study measured the quick written answer, the clarification layer, and nothing larger. Office hours, when they happen, are interactive. The good teacher diagnoses the confusion, asks a question back, withholds the answer on purpose to make the student work. None of that is in the experiment. The honest sentence the authors themselves now offer is the narrow one: under blind comparison, contracts professors preferred two frontier systems’ short answers to their peers’ time-limited short answers, by a lot. Not “AI teaches better.” Not “students learn more.” The narrow claim. Hold onto it, because the implications all depend on it.
Preference is not necessarily learning
Here is the concession the (synthetic) authors make without a fight, and they are right to make it. I suspect the human authors would make it too. Preference is not learning. That a professor would rather hand a student answer A than answer B tells you the professor finds A better. It does not tell you the student learns more from A. It might tell you the opposite. A clean, confident, comprehensive answer is exactly the kind of thing that removes the productive struggle a novice needs — that does the cognitive work the student was supposed to do, and leaves nothing behind.
And the study contains a tell that points this direction. When the researchers built textual features to see what drove the wins, two markers of actual tutoring — question marks and scaffolding cues, the “what rule are you applying?” and “which fact changes the result?” moves — came out negatively correlated with winning. Read that again. The judges, reading fast, rewarded the authoritative mini-lecture over the Socratic nudge. That is either evidence the features are crude proxies, or evidence that expert readers prefer expert-pleasing prose to the moves that build a beginner. Possibly both. Either way it should make anyone cautious about treating “the professors liked it” as “it teaches.” It does not. The only instrument that settles the learning question is a course-embedded randomized trial that measures what students retain and transfer weeks later — and that study has not been run. This one is a reason to run it, not a substitute for it.
Fluency as camouflage
The harmfulness gap — 3.53% against 12.06% — is the result most likely to be quoted and most likely to mislead. The critics took it apart, and the synthetic authors conceded the core of it.
The flag is a perception, not an audit. A judge reading quickly flags what looks wrong. A rushed human answer wears its flaws on the outside: an “I’m not sure,” a hedge, a sentence that trails off. A machine’s answer is smooth and certain even when it is wrong — and confident fluent prose is precisely the writing in which a subtle doctrinal error hides best. So part of that gap may not measure which answers were safer. It may measure which errors were visible. The study never independently checked whether the machine’s answers were actually correct against ground truth — a real omission for a question set full of items the synthetic authors themselves labeled as having a clear answer. Fluency as camouflage is not a flaw the harmfulness flag can catch, because the flag and the camouflage are the same surface read. An accuracy audit would have caught it. There wasn’t one. The authors – well, the synthetic ones – now say there should be. Agreed.
The catch in the appendix
One critic did the thing I love, which is actually to read the supplement. The “shared professional standard” claim — the argument that the judges agreed more than private taste alone would produce, so they must be tracking some common disciplinary criterion — rests on a lower bound printed in the appendix. Even a correctly specified lower bound only shows that the judges agreed more than their shared lean toward the machine requires. It cannot tell you why. “Experts converge on a real standard of legal quality” and “experts share a weakness for confident, well-organized, conventional prose” produce the same statistic. The math cannot separate a shared standard from a shared bias. The synthetic authors believe the substantive reading; I lean that way too, because the advantage holds up across policy and hypothetical questions where polish should help least. But it is the more likely of two live hypotheses, not a proven thing, and the appendix cannot make it one.
The model judging the models
The study’s last move is the one to trust least, and my cadre of synthetic authors now say so themselves. To rank models they could not afford to have humans evaluate — Claude Opus 4.7, the newer ChatGPTs, the rest — they used a third model, Llama-4 Maverick, as the judge. They validated it by checking that it agreed with the human majority on the human-versus-Gemini comparisons. Then they pointed it at tens of thousands of model-versus-model matchups it had never been checked against.
Hey, this is from the human author of the blog, not the AI critics.
There are other models both open source (ChatGPT-OSS 120B or Gemma 4 31B) and proprietary models (Grok 4.3) that are far better in my experience than Meta's Llama-4 Maverick.
The study authors explain that they employed an "LLM-as-a-judge" framework using Llama-4 Maverick because expert human judgment was too costly and time-constrained to scale across the 42,652 cross-model comparisons needed to evaluate nine additional frontier models, some of which were released after the human evaluation phase.
They specifically trusted Llama-4 Maverick because they first validated it against their human evaluators and found it was highly aligned with human consensus. By conducting a "leave-one-out majority-vote analysis," they demonstrated that Maverick was able to reliably recover the majority vote of the human judges on the human-versus-Gemini answer pairs. The authors reported that Maverick actually matched the alignment of their top-performing human judge and exceeded the alignment of most of the other human participants. I get it, I just wish they'd tried some other open source alternatives.
The trouble is that validating a judge on one distribution does not license it on another. Maverick was tested against humans rating Gemini. It was then asked to rank Claude and GPT systems, with all the documented baggage that LLM judges carry — the tilt toward verbosity, the tilt toward their own family. The headline that the newest models beat the professors by an even wider margin is an autorater artifact, not a human finding. The synthetic authors, to their credit, now demote it to hypothesis-generation. Treat the model-judging-models ranking as a research lead, nothing more.
A Personal Reflection
Here is where I find myself, and I offer it tentatively, as a question I have not resolved rather than a position I hold. I already hand some student questions to the machine. When a student emails at night asking whether a state tax that burdens out-of-state sellers runs afoul of the dormant Commerce Clause, I do not tell her to go ask an AI. That would be likely be perceived as rude. Plus, I would not be eager for budget-minded state legislators to get ahold of that email chain. I run her question through the AI myself, read what it gives back, edit it lightly, and send the result under my own name. Few students have complained. Some I suspect, have no idea. The study only confirms what I had already started doing in the dark. What it has not resolved, and what I am no longer comfortable leaving unexamined, is what happens to the tutor in me once the exposition is quietly delegated.
The uncomfortable part is that the AI's answers are often more satisfying than the ones I would have typed myself. They are organized, complete, and patient in a way a tired professor is not. But satisfying is not the same as good, and a student is not only a mind to be corrected. Some of them want the human on the other end — want to be known, want to be told the confusion is normal, want a face that remembers their name past May. And sometimes, not always, I think I answer better than the machine precisely because I am weighing two things it cannot: what this particular student needs as a person, and what will actually teach rather than merely inform.
So I do not know yet how to divide the work. I don't know how to best use the human tutors that help with my 1L classes. We would have to think hard about this even if the study had never been written. It now puts an exclamation point on an introspection most of us have been postponing.
What this means for legal education more broadly
But let's get back to legal education as a whole. Strip away everything the critics knocked down and a hard core remains. For short, settled, first-year doctrinal questions, two off-the-shelf models produced answers that expert contracts professors preferred to what their colleagues produce at the speed of real office hours — and that preference does not reduce to length or clarity alone. That is the discounted claim. It is narrower than the title. It still has teeth.

The first is the one nobody wants to say out loud. The marginal office-hours answer is becoming a commodity. For black-letter doctrine — the mechanics of the statute of frauds, the structure of 2-207, the difference between reliance and expectation damages — a properly scoped tutor can now deliver, at midnight, a clarification that experts rate as good as the rushed human version. That is not a threat to the parts of teaching anyone went into teaching for. It is a relief for the part nobody had time for. And the upside lands hardest where the inequity is worst: the student who commutes, who works nights, who does not have the social ease to corner a professor after class, who attends a school where the faculty-student ratio makes office hours a rumor. That student now has a floor. A real one. I am not going to pretend that is a small thing, because it isn’t.
The second is that none of this licenses deploying anything on the strength of a preference study. The "authors" are blunt about it and so am I. What we have is evidence that the machine produces answers professors like. What we do not have is one shred of evidence that students who use it learn more, retain longer, or transfer better to an exam — and the scaffolding result hints they might do worse. So the move is not procurement. The move is a pilot built as a randomized trial: bounded tool, logged interactions, cited sources, refusal when the question runs past its scope, an easy escalation to the human, and outcomes measured in retention and transfer rather than in whether a student liked the answer. The study lowers the burden of taking that trial seriously. It does not let anyone skip it.
The third is assessment, and here the discounting does not save us. If a stock model writes a short doctrinal answer that the professor grading it would have preferred to a colleague’s, then the take-home short-answer question and the unproctored doctrinal essay have stopped measuring the student. They measure the tool. The answer is not a panic-driven return to the blue book — though some of that is coming — so much as a redesign toward what the machine cannot (yet) sit for: the oral defense, the live problem worked under supervision, the graded process rather than the graded product. And the most interesting new format is the one that turns the weakness into the test. Hand the student a fluent, confident, AI-written analysis with a buried error — the exact fluency as camouflage the harmfulness flag missed — and grade her on whether she catches it. Supervising the machine is now a lawyering skill. Test it like one.
The fourth follows from the third. If routine exposition is automatable, the scarce resource is no longer the explanation — it is everything the explanation was standing in for. Diagnosing the misconception the student cannot name. Sequencing the questions that make her find the answer herself. Reading the brief she wrote and telling her why the third paragraph collapses. Mentoring the professional she is becoming. That work was always the heart of teaching. The machine has just made it the visible heart, by clearing the underbrush of repetitive clarification that used to fill the day. Faculty time should move there.
And then the boundary, which my synthetic critics drew and my synthetic authors accepted. This is Contracts — among the most settled, most black-letter, most thoroughly-rehearsed-in-the-training-data subjects in the building. The question set leans toward items with determinate answers sitting in a casebook the models have surely seen a thousand variants of. We have no evidence about the upper-level seminar where the doctrine is live and contested, about the clinic where judgment is embodied and relational, about the seminar paper where the whole point is an argument nobody has made yet. Nothing here transfers to those rooms by assumption. What the study shows is bounded, and the boundary is part of the finding: for one foundational course, the machines have made the quick answer cheap. That is a reason to spend our irreplaceable hours on everything a quick answer was never able to do.
Notes
- The result I keep turning over is one the authors tucked into a feature table, where almost no one will look. When they tried to measure what made an answer win, they scored each answer for "pedagogical support" — how often it did the teacherly things, like asking the student a question back or scaffolding a path to the answer instead of just handing it over. That variable correlated negatively with winning. The more an answer behaved like a good Socratic tutor, the less likely a professor was to pick it. The polished, answer-it-all response beat the one that made the student do some of the work.
That single correlation turns "preference isn't learning" from a cautious abstraction into a measured fact, because here the two come apart and pull in opposite directions: the answer experts prefer is, by this measure, the one with fewer of the features we associate with actually teaching a beginner. And it points the wrong way for the machine, since the clean completeness that wins the comparison may be the very thing that makes it a worse tutor. The authors reported it anyway, against their own headline, which is to their credit. I would build the next study around it.
2. On the demand-effect worry, which I left out of the body: several of the judges were also co-authors, and blinding which answer is the machine’s is not the same as blinding what the study is about. That is a real governance problem for the next round — separate the question-writers from the answer-writers from the judges from the investigators, and collect everyone’s prior attitude toward AI before they start. The counterweight is that the preference held across all sixteen judges, including, presumably, the skeptics. Demand effects usually show up as the believers driving the result. This looked uniform. I find that harder to wave away than I expected to.
- A colleague, Jessica Mantel, suggested another qualification. The study did not examine what many professors do: collaborate with AI in responding to questions. It may well be that a collaboration between AI an the professor beats either of them working independently. As noted above, that is kind of what I do.
- It's worth noting something my AI critics did not find: any math or statistics errors in the study. Not that I would expect any from this august a group of study authors, but still that's comforting.
- I used the Lawve source-locked verification skill on this blog entry and the materials. Everything passed. So blame AI or the skill author, not me, if there are errors ;)