
Now, even law professors can do serious data analysis
A law professor opens a spreadsheet — exam scores, structured data on shareholder oppression cases, a court database — and senses there is something in it worth knowing. Then the file just sits there. The professor is not alone. Law students, judges, court administrators, and practicing lawyers hit the same wall: they suspect the numbers matter, but they have never felt at home working the numbers themselves. So the question goes unasked, or it gets handed to someone who bills by the hour.
Claude for Excel, available for free so long as you have a paid Claude subscription, lowers that wall. It does not promise to make anyone a statistician. It promises something smaller and more useful: a way to start.
The experiment here shows how much you can now do without leaving Excel — from simple sorting to pivot tables to serious statistical or machine learning analysis. You no longer have to hire an expert, learn a statistical language, or farm out the first pass. You ask questions in plain English, poke at the patterns, test a hunch, and see whether it holds — inside a tool with which most lawyers already have some degree of familiarity and on which probably over a billion dollars has been spent over decades refining its capabilities and assuring its reliability. Moreover, the workflow is reproducible and auditable. It doesn't depend on various unrecorded interactions between the mouse and the user interface.
None of this quite yet makes experts obsolete —serious empirical work and litigation-grade analysis still need specialists —but lawyers and legal academics can get much further on their own before paying for one. But it does mean that lawyers and legal academics can do much more before reaching that point. So too can academic administrators – think admissions office, development, registrars – and law students – think law journal or advocacy course management. And it lets you demand more of your expert. If Claude for Excel knows statistics or can manipulate a spreadsheet better than your expert, maybe it's time to find a new expert.
The point of this experiment is not to test the outer limits of AI-driven data analysis. It is to lower the barrier to entry. People in law should become more courageous about data. The spreadsheet is not a mysterious technical object. With AI alongside, Excel becomes a practical place to start asking empirical questions. Let me prove it to you.
The Supreme Court Database Experiment
Data Prep
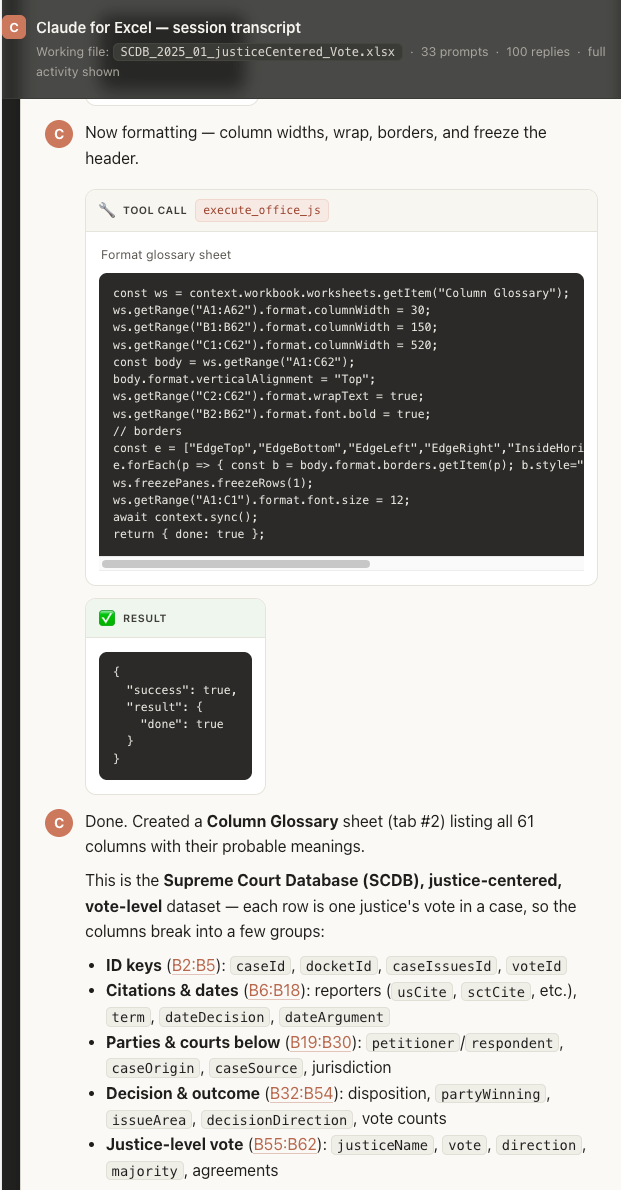
The data I started with comes from the United States Supreme Court. I chose it for three reasons: many of my readers care about the Court, most already have intuitions about how it behaves, and it sits in a Goldilocks zone of complexity: a one-sheet spreadsheet with 125,464 rows and 61 columns that covers the 1946 through 2025 terms. Getting it was simple. The Supreme Court Database, now housed at Penn State, downloads as an .xlsx file; I opened it in Excel and turned on the Claude for Excel add-in; there's an excellent installation video here. A spreadsheet now filled the left panel, with an AI companion ready on the right.
Time to explore. I entered the text set forth below in the Claude for Excel prompt. Having an understanding of the meaning of the column names is important because it lets me say things like "figure out the affirmance and reversal counts for cases from three judge federal courts by term" without having to tell Claude exactly what columns each of those concepts or terms maps to. Notice that I did not tell the AI how to figure out what the column names meant. I wanted to see what it could do on its own.
Give me a list of all of the column names and what they probably mean. Put the results in a new sheet
Claude for Excel then used a combination of operations native to Excel and Claude's ability to use Javascript to create the task. Here's a screenshot of the new sheet.

When I asked how Claude derived the meanings of the column, it responded as shown below. Notice that Claude is already going beyond the capabilities of most conventional spreadsheets or data analysis programs because it is applying its own intelligence and web research capabilities.
The meanings were not pulled from a connector or web search — they came from my own knowledge. I recognized the filename (SCDB_..._justiceCentered_Vote) and the column names (caseId, naturalCourt, lcDispositionDirection, majOpinWriter, justiceName, etc.) as the Supreme Court Database (SCDB) — a well-known, publicly documented political-science dataset of U.S. Supreme Court decisions. Its codebook is established enough that I know the field definitions directly.
Dissent Counts
Here's a relatively simple starter experiment.
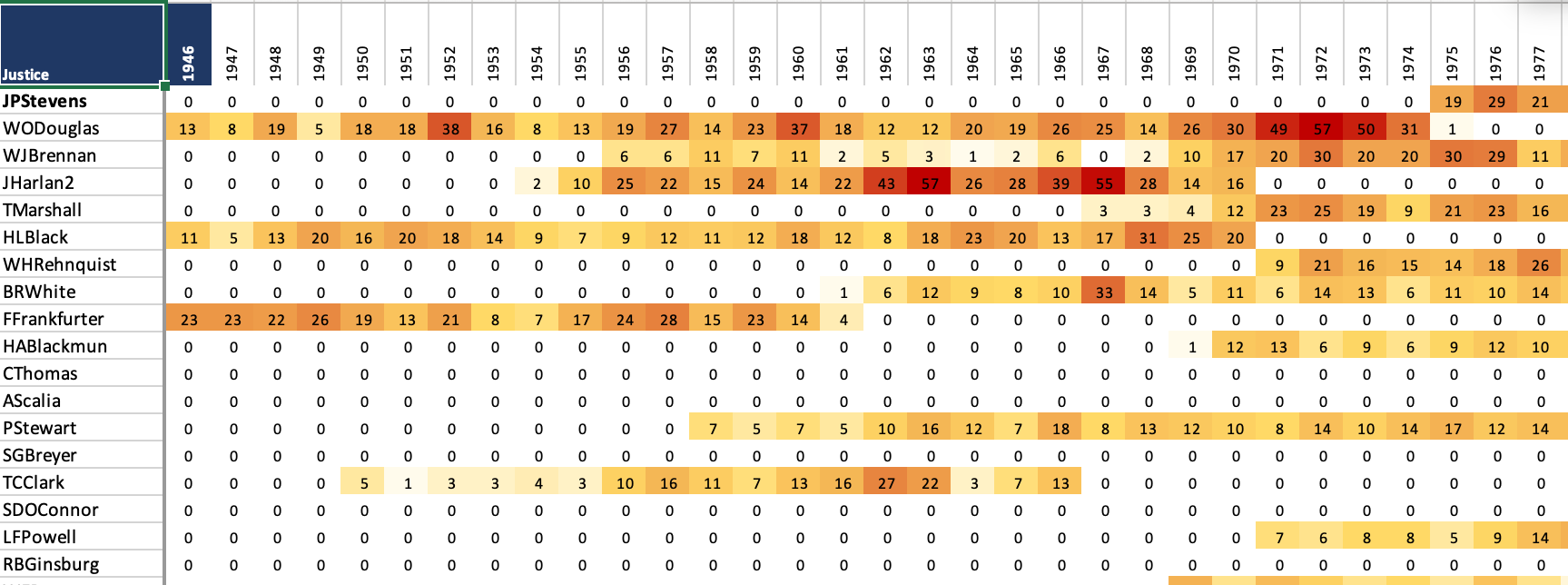
Use Excel functions only to calculate for each justice the number and type of dissenting opinions they authored each term. Produce a sheet in which the rows are the justices and the columns are the terms. Represent a zero as a zero.
The result is an attractive table; a screen capture is provided below.
One virtue of manipulating data with an AI is that you get an auditable trail of actions. It's more like a Colab or Wolfram Notebook in that respect for those familiar with those surfaces. I asked Claude for Excel to summarize its work. Here is the result.
What I built
Two sheets, all in Excel formulas:
- Dissents by Term — rows = the 40 justices (sorted by career total), columns = terms 1946–2024. Each cell is the number of dissenting opinions that justice authored that term (zeros shown as
0). On the right: a Total column plus three type columns — Regular (vote 2), Cert‑denial (vote 6), Jurisdictional (vote 7). - Dissent Calc — the helper layer that flags each row.
Definition: an authored dissent = the justice wrote or co‑authored an opinion (opinion ∈ {2,3}) and cast a dissenting vote (vote ∈ {2,6,7}).
Leaderboard (career authored dissents): Stevens 727 · Douglas 666 · Brennan 499 · Harlan II 440 · Marshall 394 · Black 382. Total across the Court: 7,400.
The one subtlety that mattered
The file isn't one row per justice per case — it repeats each justice across a case's consolidated dockets/issues (~13 rows per case). Since vote/opinion are case‑level, naively counting rows overcounted by ~64% (12,151 vs the true 7,400). So I deduped to one record per justice‑case before counting.
Key Excel code
Helper (Dissent Calc) — pick one record per case, then flag authored dissents:
BlockFlag (col H):
=--('Data'!C2:C125464 = XLOOKUP('Data'!A2:A125464,'Data'!A2:A125464,'Data'!C2:C125464,,0,2))XLOOKUP(…,,0,2) does a binary search on the sorted caseId column, returning one consistent caseIssuesId per case — so BlockFlag keeps exactly one docket/issue block per case (one row per justice‑case).
Total dissent flag (col C):
= H2# * (('Data'!BE2:BE125464=2)+('Data'!BE2:BE125464=3)) ' authored
* (('Data'!BD2:BD125464=2)+('Data'!BD2:BD125464=6)+('Data'!BD2:BD125464=7)) ' any dissent
' columns D/E/F swap the last factor for (BD=2), (BD=6), (BD=7) to split by typeMatrix (Dissents by Term):
Term headers (B1): =SEQUENCE(1,79,1946,1)
Justice list (A2): =LET(J, UNIQUE(FILTER('Dissent Calc'!A2:A125464,'Dissent Calc'!A2:A125464<>"")),
tot, MAP(J,LAMBDA(j,SUMIFS('Dissent Calc'!$C$2:$C$125464,'Dissent Calc'!$A$2:$A$125464,j))),
SORTBY(J,tot,-1))
Cell (B2): =SUMIFS('Dissent Calc'!$C$2:$C$125464,
'Dissent Calc'!$A$2:$A$125464, $A2,
'Dissent Calc'!$B$2:$B$125464, B$1)
Type totals (CD2): =SUMIFS('Dissent Calc'!$D$2:$D$125464,'Dissent Calc'!$A$2:$A$125464,$A2)SUMIFS returns 0 for justice‑terms with no authored dissents, which is why every empty cell shows a real zero rather than a blank.
I can then refine the result.
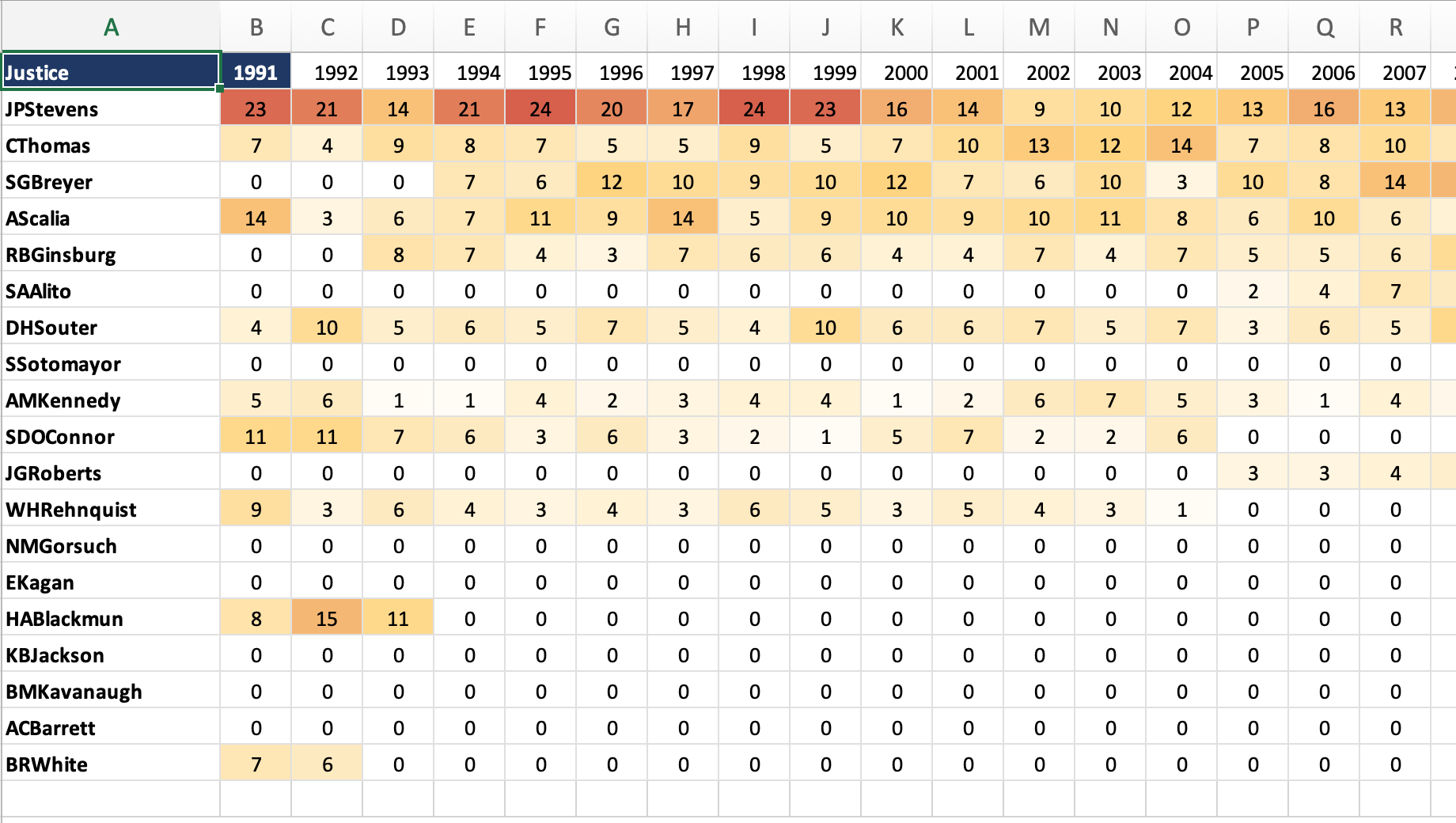
Look up the term when Justice Thomas joined the court. Now filter the output so that it includes only years on or after that term and only Justices who had any dissents from that date to the present.
Claude for Excel explains its process. Those familiar with Excel will recognize that Claude is using some sophisticated methodology, including use of functional programming via lambda expressions. Go Claude!
Done. New sheet Dissents 1991+ — the same dissent matrix filtered to Thomas's first term (1991) onward and to the 19 justices who authored at least one dissent in that window.
- Columns: terms 1991–2024, plus Total + the three type columns.
- Rows: 19 justices, sorted by their 1991‑onward dissent total.
Top dissenters since 1991: Stevens 319 · then Thomas, Scalia, Ginsburg, Breyer, Alito (the matrix sorts them top‑to‑bottom). Justices who served only briefly into this window (White, Blackmun) appear near the bottom with small counts but still qualify.
The filter is driven by a single condition added to the justice list — keep a justice only if their dissents from 1991 on are positive:
=LET( J, UNIQUE(FILTER('Dissent Calc'!A2:A125464,'Dissent Calc'!A2:A125464<>"")),
tot, MAP(J,LAMBDA(j, SUMIFS('Dissent Calc'!$C$2:$C$125464,
'Dissent Calc'!$A$2:$A$125464, j,
'Dissent Calc'!$B$2:$B$125464, ">=1991"))),
SORTBY( FILTER(J, tot>0), FILTER(tot, tot>0), -1) )The ">=1991" criterion in SUMIFS does both jobs — it restricts the term window and (via tot>0) drops any justice with no dissents in that span. The grid columns start at 1991 (=SEQUENCE(1,34,1991,1)), and the original full Dissents by Term sheet is untouched.
Here's a screen capture of the output through the 2007 term.
A pivot table
Another classic tool for data analysis is the "Pivot table." Wikipedia reasonably defines this as: "a table of values which are aggregations of groups of individual values from a more extensive table (such as from a database, spreadsheet, or business intelligence program) within one or more discrete categories. The aggregations or summaries of the groups of the individual terms might include sums, averages, counts, or other statistics. A pivot table is the outcome of the statistical processing of tabularized raw data and can be used for decision-making." It's a staple of work in Excel.
The discussion below shows how Claude for Excel creates a pivot table of issue area against the "decision direction," whether the Court's ruling is best classified as liberal or as conservative.
Here's the proposal, built and ready on the Pivot sheet.
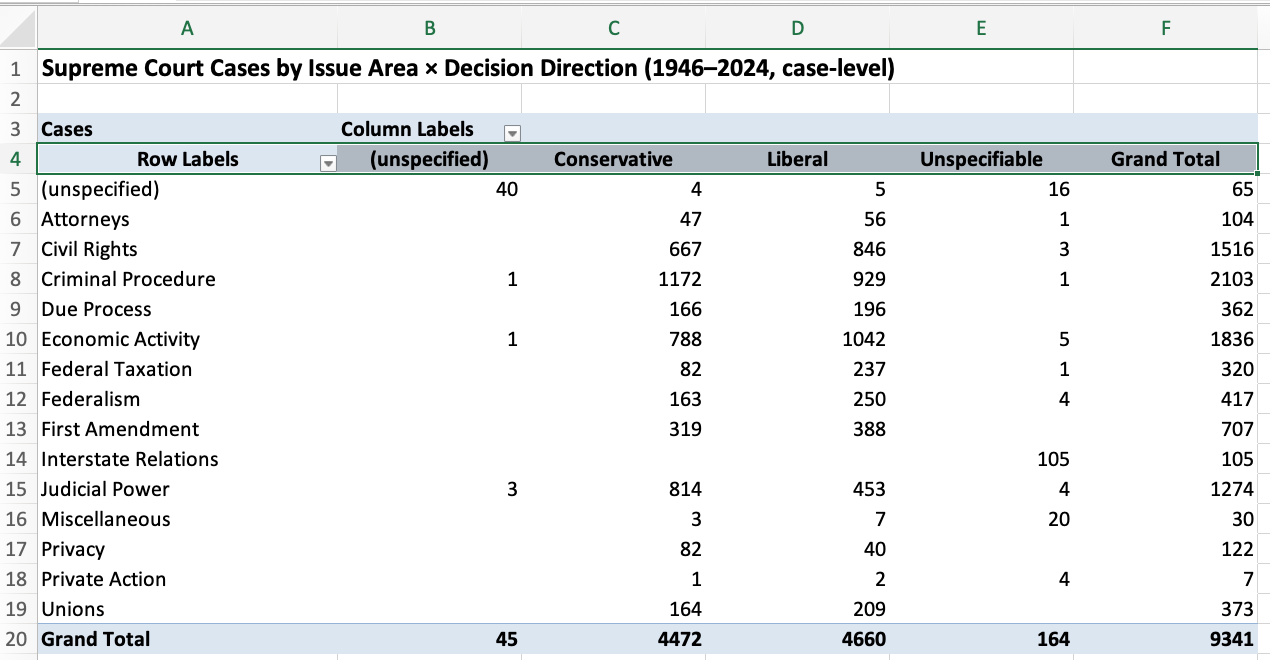
The pivot: Issue Area × Decision Direction
A genuinely classic SCDB cut — what the Court decides, and which way it leans:
- Rows: Issue Area (Criminal Procedure, Civil Rights, Economic Activity, …)
- Columns: Decision Direction (Conservative / Liberal / Unspecifiable)
- Values: Count of cases
What it shows (1946–2024, 9,341 cases):
| Issue Area | Cases | Cons. | Lib. |
|---|---|---|---|
| Criminal Procedure | 2,103 | 1,172 | 929 |
| Economic Activity | 1,836 | 788 | 1,042 |
| Civil Rights | 1,516 | 667 | 846 |
| Judicial Power | 1,274 | — | — |
| First Amendment | 707 | — | — |
Overall the Court tilts slightly liberal — 4,660 vs 4,472 conservative — but the lean flips by topic: criminal-procedure cases skew conservative, while economic and civil-rights cases skew liberal. That contrast is the whole story of the dataset in one table.
Why it needed a setup step
A PivotTable runs on whatever range you give it, and the Data sheet is vote-level (each case repeats ~13× across justices and dockets/issues). Pivoting it directly would have reported ~125k "cases." So I built a one-row-per-case source first:
- Case Table — deduped to 9,341 cases with
=FILTER('Data'!…, A2:A<>A1:A)(keep the first row of each case), thenXLOOKUPto turn the numericissueAreaanddecisionDirectioncodes into readable labels. - Pivot — a native PivotTable on
Case Table!A1:D9342, Count of caseId.
The Grand Total reads 9,341, confirming it's counting cases correctly. Because it's a real PivotTable, you can now drag fields around — swap Decision Direction for Term or Chief Justice, or drop Issue Area into the filter — and it'll recompute instantly. Want me to add a second pivot (say, cases by Chief Justice era), or a pivot chart off this one?
Here is the output. It shows a greater tendency to "conservative" outcomes in criminal procedure cases and judicial power cases whereas decisions in economic activity seem to be labeled "liberal" more frequently. The main point, however, is that construction of a pivot table is now only an English sentence away.
Justice-Justice Agreement
I then asked a more complex question of the data. I wanted to do the classic justice-agreement experiment where you see which justices agree with each other over time. But I imagined that I was not quite sure how to ask the question. Perhaps I could have done all the work inside of Claude for Excel but I decided to ask Claude Cowork outside of the Excel session: "Suppose we just put together an agreement table by year. We could do that, right? But would we have one sheet per year? That seems excessive. What's the best way?" I then followed up an interim response with: "What should I tell Claude for Excel to generate the long tidy sheet. I want Claude for Excel to figure out the formulae. Don't you tell me." It was then that I gave Claude for Excel the prompt set forth below.
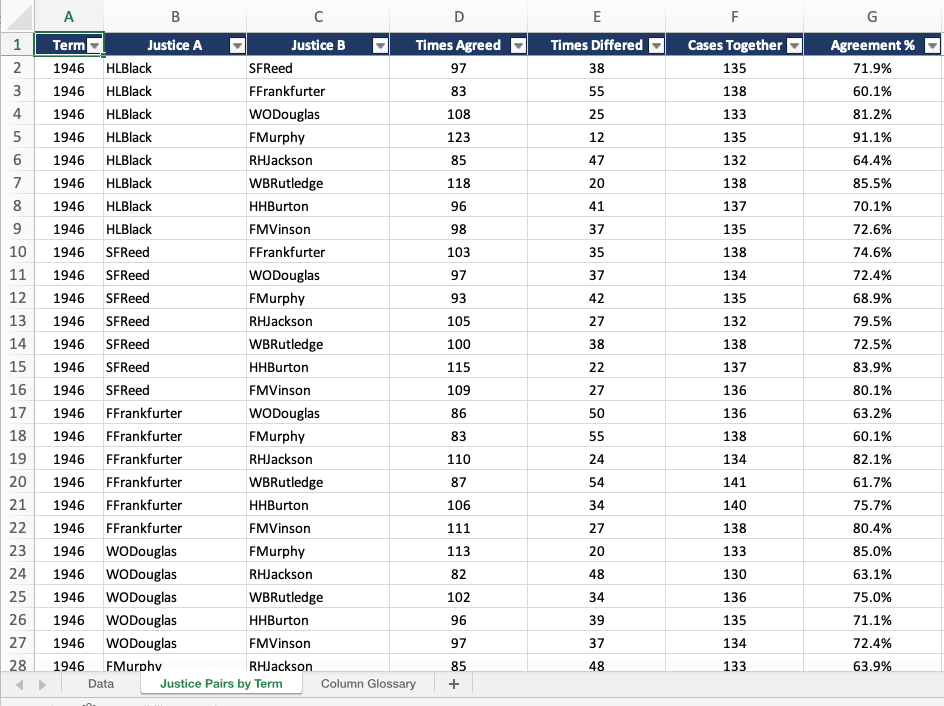
Make me a tidy sheet with one row per pair of justices per term showing how often they voted together and how often they voted differently. And show me the Excel code you used to do this.
The result was a new sheet that Claude for Excel sensibly named Justice Pairs by Term.
Claude for Excel explained that it has used Javascript rather than pure Excel to perform the task. So, not only is Claude doing a lot of work in response to a simple English-language request, it is going beyond what the average Excel programmer could do on their own. Here's the response I got in Claude for Excel.
It's not cell formulas — the agreement counts require a self-join (matching every justice against every other justice within the same case across 125k rows), which Excel formulas handle poorly at this scale. So I read the data with Office.js and computed the pairwise tallies in JavaScript, then wrote the summary table back. The core logic:
// 1. Read the 4 needed columns for all 125,463 rows, in chunks of 25k
// A=caseId, K=term, BB=justice, BC=justiceName, BG=majority (1=dissent, 2=majority)
// 2. Group votes by case, deduping to one vote per justice per case
const cases = new Map(); // caseId -> {term, seen:Set, parts:[{id,maj}]}
for (let i = 0; i < n; i++) {
const m = maj[i];
if (m !== 1 && m !== 2) continue; // skip non-participation
let c = cases.get(caseId[i]) ?? {term: term[i], seen: new Set(), parts: []};
if (c.seen.has(jid[i])) continue; // dedupe consolidated dockets/issues
c.seen.add(jid[i]);
c.parts.push({id: jid[i], maj: m});
cases.set(caseId[i], c);
}
// 3. For every case, compare each pair of participating justices
const agg = new Map(); // "term|justiceA|justiceB" -> {agree, diff}
for (const c of cases.values()) {
const p = c.parts;
for (let a = 0; a < p.length; a++)
for (let b = a + 1; b < p.length; b++) {
let [A, B] = p[a].id < p[b].id ? [p[a].id, p[b].id] : [p[b].id, p[a].id];
const key = c.term + "|" + A + "|" + B;
const r = agg.get(key) ?? {term: c.term, A, B, agree: 0, diff: 0};
if (p[a].maj === p[b].maj) r.agree++; else r.diff++; // same side vs opposite
agg.set(key, r);
}
}
// 4. Sort by term, then justice; write A:E as values, F & G as formulas (=D+E, =D/F)A caveat worth knowing: for the rare cases with split votes (a justice in the majority on one issue but dissenting on another under the same caseId), I take the justice's first record — standard for case-level agreement, but it's an approximation. Want me to add a sortable "most/least agreeable pairs" view, or switch the agreement definition to ideological-direction agreement (direction field) instead of majority/dissent side?
Justice-Justice Drift
I then wanted to explore whether there was statistical support for the idea of justices drifting apart from each other or towards each other over time. So, I asked the following questions. In some sense I may have cheated by using knowledge of statistics to request a p-value, but otherwise there is nothing particularly technical about the request. It mostly requires an idea, perhaps one that could have been sculpted inside of Claude for Excel or an external large language model.
For each justice pair that sat together at least 8 terms, fit a trend line of Agreement % over Term. Show me the ones with the largest (in absolute value), statistically significant drift — give me the slope, the p-value, and the change from first term to last. Sort by size of drift, and weight by cases where you can. Put the results in a separate sheet and tell me the excel formula or other code you used to do the work
Claude then did some sophisticated work using Javascript and statistics libraries, including adjustment of p-values using Benjamini-Hochberg (BH) methodology. Honestly, although I would have been sensitive to the problems of using p-values when dozens of regressions are being run – I do, after all, periodically teach a course called Analytic Methods for Lawyers – I was not aware of the Benjamini-Hochberg adjustment procedure. So not only is Claude for Excel permitting me to use English as a data analysis language, it is doing so better than even someone who thinks of themselves as very good with data (at least in the law professor world).
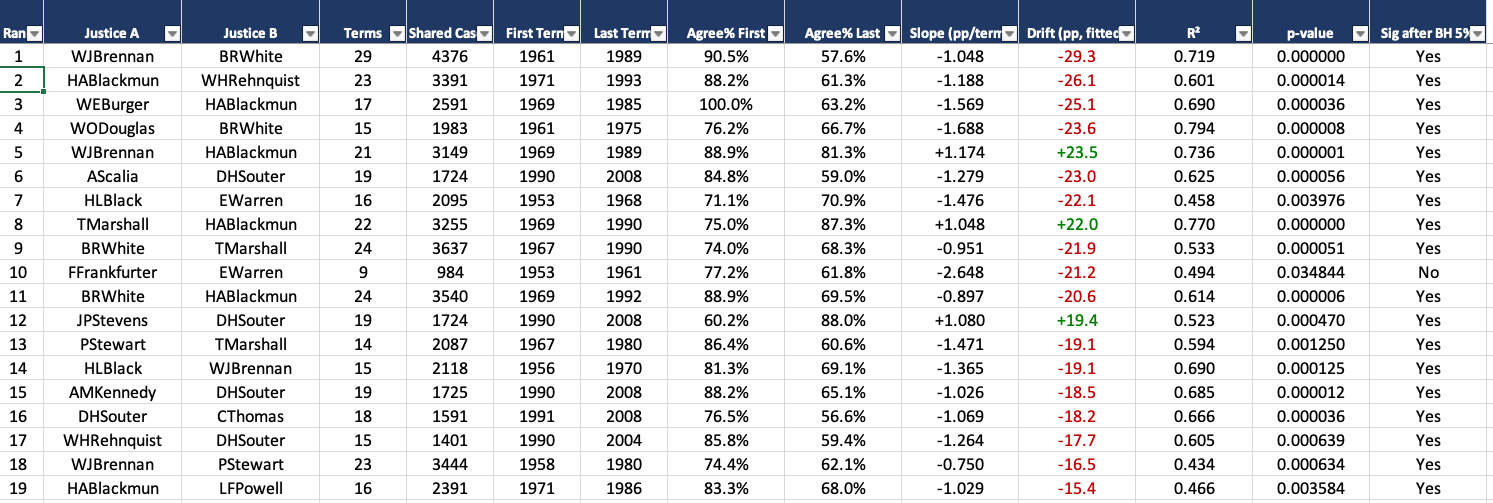
Done. New sheet Pair Drift (Significant) — 41 justice pairs (of 154 with ≥8 shared terms) whose agreement trend over time is significant at p<0.05, sorted by absolute drift.
Columns: Rank · Justice A/B · Terms · Shared Cases · First/Last Term · Agree% First/Last · Slope (pp/term) · Drift (pp, fitted) · R² · p-value · Sig after BH 5%. Drift is red for diverging pairs, green for converging.
Biggest movers (all BH-significant):
- Brennan–White –29.3 pp (1961→89): 90% → 58% agreement as White drifted right while Brennan stayed left
- Blackmun–Rehnquist –26.1 pp and Burger–Blackmun –25.1 pp: Blackmun's well-documented leftward migration away from the Nixon bloc
- Douglas–White –23.6 pp
- Brennan–Blackmun +23.5 pp and Marshall–Blackmun +22.0 pp: the flip side — Blackmun converging with the liberals
- Scalia–Souter –23.0 pp, Kennedy–Souter –18.5 pp, Souter–Thomas –18.2 pp: Souter's leftward shift after 1990
The Blackmun and Souter stories dominate, in both directions — exactly what you'd expect from two justices who moved a lot relative to stationary colleagues.
How it was computed
Per pair, a weighted least-squares regression of Agreement % on Term, weighting each term's point by Cases Together that term (terms with more shared cases are more reliable estimates — and since the variance of a proportion ∝ 1/n, case-count is a natural inverse-variance weight). The math, run in JavaScript over the Justice Pairs by Term data:
W = Σ wᵢ (wᵢ = cases shared in term i)
x̄ = Σwᵢxᵢ / W ; ȳ = Σwᵢyᵢ / W (xᵢ = term, yᵢ = agreement %)
Sxx = Σwᵢ(xᵢ−x̄)² ; Sxy = Σwᵢ(xᵢ−x̄)(yᵢ−ȳ)
slope b = Sxy / Sxx → drift per term
Drift = b × (lastTerm − firstTerm)
SSE = Σwᵢ(yᵢ − a − b·xᵢ)² ; σ² = SSE/(n−2)
SE(b) = √(σ²/Sxx) ; t = b / SE(b) , df = n−2The two-sided p-value = 2·(1 − T_cdf(|t|, df)) and the Benjamini-Hochberg false-discovery-rate adjustment (last column) were computed with scipy.stats — equivalent Excel formulas would be =T.DIST.2T(ABS(t), df) for the p-value. I used code rather than cell formulas because the agreement counts require a self-join of every justice against every other within each case across 125k rows, which Excel formulas handle poorly at that scale.
Two caveats: (1) the p-value treats weights as known reliabilities (standard analytic-weight WLS); (2) with 154 simultaneous tests, ~8 false positives are expected at p<0.05 — hence the BH column, where 25 of the 41 survive FDR control. Lean on those 25 for any firm claims.
Want me to add a scatter+trendline chart for any specific pair, or rank instead by slope magnitude rather than total drift?
Here's a screen capture of new "Pair Drift (significant)" sheet that Claude for Excel created from this process. (I increased the font size to make it easier to read here)
Composite Drift
I then wanted to see if we could get a handle not just on justice-justice drift but on justice drift itself. That is, if Justice X was wandering off away from lots of justices that might indicate a change in their ideology over the years. I was looking to make more scientific commonplaces about, for example, the leftwards movement of Justice Blackmun. Some exploratory work with Claude Cowork ultimately led to this prompt inside Claude for Excel.
From the pair-drift results, rank the individual justices by how much their agreement relationships changed overall — average the absolute drift across each justice's pairs, weight by shared cases, and show me who moved most. Create a separate sheet.
Claude for Excel then gave me a verbal answer. Yes, Justice Blackmun moved the most followed by Justice Souter's leftward journey and Justice White's rightwards one. It likewise explained its methodology.
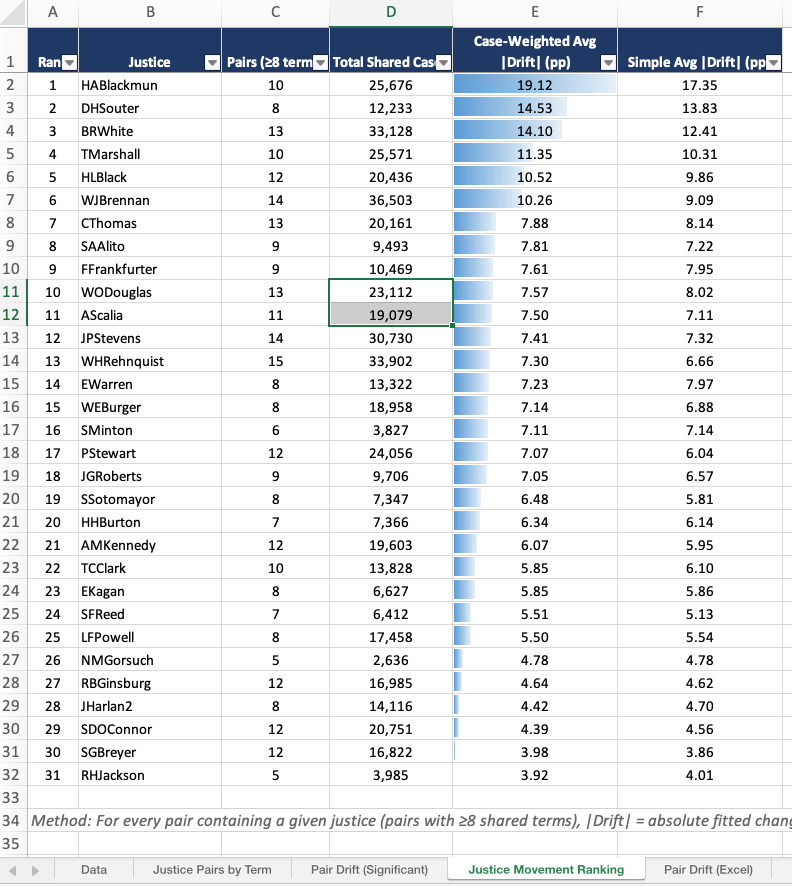
Done. New sheet Justice Movement Ranking — all 31 justices ranked by how much their voting relationships shifted, using all 154 pairs (≥8 shared terms).
Columns: Rank · Justice · Pairs · Total Shared Cases · Case-Weighted Avg |Drift| (pp, with data bar) · Simple Avg |Drift| (pp).
Who moved most:
| # | Justice | Wtd avg |drift| |
|---|---|---|
| 1 | Blackmun | 19.1 pp |
| 2 | Souter | 14.5 pp |
| 3 | White | 14.1 pp |
| 4 | Marshall | 11.4 pp |
| 5 | Black | 10.5 pp |
| 6 | Brennan | 10.3 pp |
Most stable: Breyer (4.0), Jackson (3.9), O'Connor (4.4), Harlan II (4.4), Ginsburg (4.6).
Blackmun and Souter at the top is the expected result — both are the textbook cases of justices who drifted left over a career. White's #3 reflects his rightward move relative to the liberal bloc he started with. Marshall and Brennan rank high largely because their partners moved around them (their own positions were stable, but the relationships still changed).
Method: for each justice, Σ(sharedCases × |Drift|) / Σ(sharedCases) across their qualifying pairs, where |Drift| is the absolute fitted change in agreement from first to last shared term. The full formula is in the note on each sheet. One caveat flagged on the sheet: Gorsuch (5 pairs), Jackson (5), and Minton (6) rest on thin samples.
Want a horizontal bar chart of this ranking, or a per-justice breakdown showing which specific relationships drove each justice's score?
Here's a screen capture of the new sheet. Claude for Excel even formatted it nicely.
When I asked it for details on how it had done the work, Claude provided them. One of the many advantages of working with data this way is that it provides an auditable trail of what was done. It's almost like a Wolfram notebook or the similar subsequent notebook interface available in Jupyter and its derivatives such as Google Colab and other software.
Straight answer: the heavy computation was not done with Excel formulas — it ran in JavaScript (Office.js), with one step in Python. Here's exactly what ran where.
| Step | Where | Why |
|---|---|---|
| Pairwise agree/differ counts (per pair per term) | JavaScript | Needs a self-join of every justice against every other within each case across 125k rows — Excel formulas handle that badly |
Cases Together, Agreement % on the Justice Pairs by Term sheet |
Excel formulas (=D+E, =D/F) |
Simple derived cells — live and auditable |
| Weighted regressions (slope, drift, t-stat) | JavaScript | One WLS fit per pair |
| p-values + Benjamini-Hochberg | Python / scipy | Exact t-distribution + FDR adjustment |
| This justice ranking (case-weighted avg |drift|) | JavaScript | Aggregating the 154 pair drifts |
So the numbers on the ranking sheet are computed values, not formulas. The exact JavaScript that produced this latest sheet:
// 1. Read Term, Justice A/B, Cases Together, Agreement % from "Justice Pairs by Term"
const pairs = new Map(); // "A|B" -> [{x:term, y:agree%, w:cases}]
for (const row of values) {
const [term, jA, jB, , , cases, agr] = row;
if (typeof term !== "number" || typeof agr !== "number") continue;
(pairs.get(jA+"|"+jB) ?? pairs.set(jA+"|"+jB, []).get(jA+"|"+jB))
.push({ x: term, y: agr, w: cases > 0 ? cases : 1 });
}
// 2. Per pair (>=8 terms): weighted least-squares slope, then |drift| = |slope x span|
const perPair = [];
for (const [key, pts] of pairs) {
if (pts.length < 8) continue;
let W=0, Sx=0, Sy=0;
for (const p of pts) { W+=p.w; Sx+=p.w*p.x; Sy+=p.w*p.y; }
const xb=Sx/W, yb=Sy/W;
let Sxx=0, Sxy=0;
for (const p of pts) { const dx=p.x-xb; Sxx+=p.w*dx*dx; Sxy+=p.w*dx*(p.y-yb); }
if (Sxx <= 0) continue;
const b = Sxy / Sxx; // slope (agreement fraction per term)
const xs = pts.map(p=>p.x), span = Math.max(...xs) - Math.min(...xs);
const [jA, jB] = key.split("|");
perPair.push({ jA, jB, drift: Math.abs(b*span), cases: W });
}
// 3. Aggregate per justice: case-weighted mean of |drift|
const J = new Map();
for (const pp of perPair)
for (const name of [pp.jA, pp.jB]) {
const g = J.get(name) ?? J.set(name, {n:0, cases:0, wsum:0, usum:0}).get(name);
g.n++; g.cases += pp.cases;
g.wsum += pp.cases * pp.drift; // numerator: Σ cases·|drift|
g.usum += pp.drift;
}
// 4. Score = Σ(cases·|drift|) / Σ(cases); sort descending
const out = [...J].map(([name,g]) =>
[name, g.n, Math.round(g.cases), +(g.wsum/g.cases*100).toFixed(2), +(g.usum/g.n*100).toFixed(2)]
).sort((a,b)=>b[3]-a[3]);The case-weighting is the g.wsum/g.cases line — step 4's Σ(cases × |drift|) / Σ(cases).
If you'd rather have this fully native in Excel so every number traces to a formula, I can drop all 154 pairs (with their |drift| and shared-case weight) onto a helper sheet and compute each justice's score with SUMPRODUCT — e.g. for a justice in cell $H2:
=( SUMPRODUCT((Pairs[A]=$H2)*Pairs[Cases]*Pairs[AbsDrift])
+ SUMPRODUCT((Pairs[B]=$H2)*Pairs[Cases]*Pairs[AbsDrift]) )
/( SUMPRODUCT((Pairs[A]=$H2)*Pairs[Cases])
+ SUMPRODUCT((Pairs[B]=$H2)*Pairs[Cases]) )Want me to build that native version?
Reversal Rates By Federal Court
Time to shift gears. Here's a new inquiry. The query isn't simple because the rows in the underlying data are by case, issue and justice and I am asking a question about cases. It also has to decide which of the petitioner categories have enough cases s
New task. For cases coming from one of the federal courts of appeal, for each such court and each term are you able to compute reversal rate and put it in a new sheet?
Here's the work Claude for Excel did. Again, you can see Claude doing some significant work here. And, it exposes its choices if one suspects an error.
Done. New sheet CoA Reversal with reversal rate for each federal court of appeals × each term (1946–2024), all in Excel formulas.
Layout:
- Rate grid (
B6:N84) — terms down the rows, the 13 circuits across columns (1st–11th, D.C., Federal), color-scaled. Cells with fewer than the threshold inB2(default 3) cases that term are left blank. - All-terms summary (
row 85–86) — each circuit's overall reversal rate and total cases. - Case-count grid (rows 90–169) — N per cell so you can see which rates are solid.
Overall reversal rate by circuit (1946–2024):
| Circuit | Rate | Cases |
|---|---|---|
| 9th | 73.9% | 1,067 |
| D.C. | 72.0% | 461 |
| 6th | 69.4% | 496 |
| Federal | 69.2% | 117 |
| 5th | 68.5% | 685 |
| 8th | 67.5% | 345 |
| 10th | 66.3% | 279 |
| 7th | 63.1% | 461 |
| 11th | 62.0% | 229 |
| 4th | 61.4% | 370 |
| 3rd | 60.7% | 402 |
| 1st | 60.2% | 181 |
| 2nd | 57.2% | 624 |
The Ninth Circuit is the most-reversed (73.9%, and by far the most cases), with the D.C. Circuit second — both well-known patterns. The Second Circuit is the least reversed (57.2%).
The formula (rate cell, term in $A6, circuit code in B$4):
=LET( c, SUMPRODUCT(('Case Calc'!$B$2#=$A6)*('Case Calc'!$H$2#=B$4)*'Case Calc'!$G$2#),
r, SUMPRODUCT(('Case Calc'!$B$2#=$A6)*('Case Calc'!$H$2#=B$4)*'Case Calc'!$F$2#),
IF(c < $B$2, "", r/c) )I added one field to Case Calc — H2 =FILTER('Data'!AB2:AB125464, mask) — to carry each case's source court (caseSource) alongside the existing term and reversal/denominator flags.
Two notes: (1) Per-term-per-circuit counts are small, so many single-term rates are noisy — lean on the counts grid and the all-terms summary. (2) I couldn't apply frozen header panes because the other open workbook (admissions.xlsx) kept grabbing focus; the data and formatting are all in place. Want me to add a trend chart of the 9th vs 2nd Circuit reversal rate over time?
And here are the results as they appear in the spreadsheet itself.
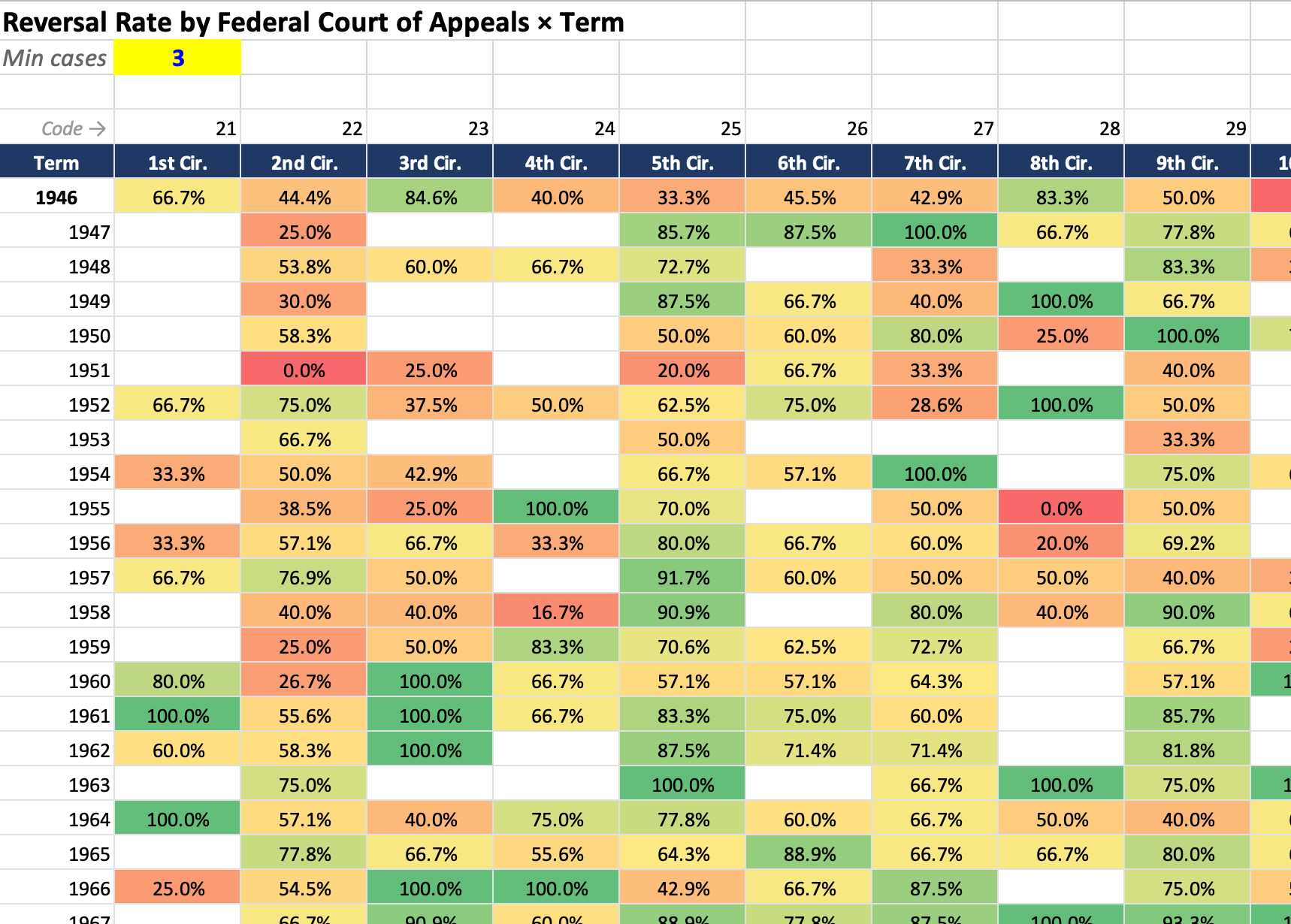
Reversal Rates By Type of Petitioner
I also decided to investigate whether certain types of petitioners had greater success in obtaining reversals. Again, I am asking for more than mere mechanical Excel work. Claude has to decide which of the petitioner categories have enough cases so that a conclusion would be meaningful.
Using the case-level data, show me reversal rate by type of petitioner, broken out by decade. Group the petitioner categories into a manageable number of buckets, only count cells with enough cases to be meaningful, and tell me which petitioner types the Court favored most in each decade. Try to do it without Javascript or Python but just using Excel functionality and show me the code you ended up using. If you can’t do it in Excel, just tell me that and show me the code you did use.
Done — all in Excel formulas, no JavaScript/Python in the computation. Three new sheets:
- Reversal by Decade — the result: reversal rate for each petitioner type × decade, with a "Most Favored" column.
- Pet Buckets — the 311 SCDB petitioner codes mapped to 6 buckets (editable lookup table).
- Case Calc — case-level helper (deduped from the 125k vote rows to 9,341 cases).
Definitions: Reversal = the Court reversed or vacated the decision below (disposition 3, 4, 5, 8); rate = reversals ÷ affirm-or-reverse cases (2, 3, 4, 5, 8). Reversal favors the petitioner (who sought review), so the highest-rate bucket each decade is the one the Court "favored most." Cells with fewer than 15 cases (threshold in B3, adjustable) are blanked.
Who the Court favored most, by decade:
| Decade | Most favored | Rate |
|---|---|---|
| 1940s–1990s | Federal Government | ~75–86% |
| 2000s | State/Local Government | 82.8% |
| 2010s | State/Local Government | 76.2% |
| 2020s | State/Local Government | 88.4% |
The clear story: the federal government was the Court's most-reversed-for petitioner for five straight decades (when the US asks the Court to reverse, it usually does), then state & local governments overtook it in the 2000s. Business and individual petitioners run lower (~50–75%). Other/Foreign is mostly suppressed for thin samples.
The key formulas (all Excel):
Case-level dedup — the data is sorted by case, so a row starts a new case when its caseId differs from the row above:
Case Calc!A2: =FILTER('Data'!R2:R125464, 'Data'!A2:A125464 <> 'Data'!A1:A125463) ' petitioner, 1 row/case
D2: =FLOOR(B2#, 10) ' decade
E2: =XLOOKUP(A2#, 'Pet Buckets'!$A$2:$A$312, 'Pet Buckets'!$C$2:$C$312, "Other/Foreign")
F2: =IF((C2#=3)+(C2#=4)+(C2#=5)+(C2#=8)>0, 1, 0) ' reversal flag
G2: =IF((C2#=2)+(C2#=3)+(C2#=4)+(C2#=5)+(C2#=8)>0, 1, 0) ' denominator flagRate cell (decade in $A6, bucket in B$5), with the case threshold:
=LET( c, SUMPRODUCT(('Case Calc'!$D$2#=$A6)*('Case Calc'!$E$2#=B$5)*'Case Calc'!$G$2#),
r, SUMPRODUCT(('Case Calc'!$D$2#=$A6)*('Case Calc'!$E$2#=B$5)*'Case Calc'!$F$2#),
IF(c < $B$3, "", r/c) )Most-favored bucket per decade:
=IFERROR(INDEX($B$5:$G$5, MATCH(MAX(B6:G6), B6:G6, 0)), "")One caveat: the 6-bucket assignment of 311 codes (Federal / State-Local / Business / Individual-Employee / Criminal / Other-Foreign) is a judgment call — I classified each official label, and the full mapping is on the Pet Buckets sheet so you can re-bucket any code and everything recalculates.
Want me to add a chart of the favored-type trend, or split out a "Criminal defendant" vs "Business" comparison line over time?
Here's a screen capture of the results.
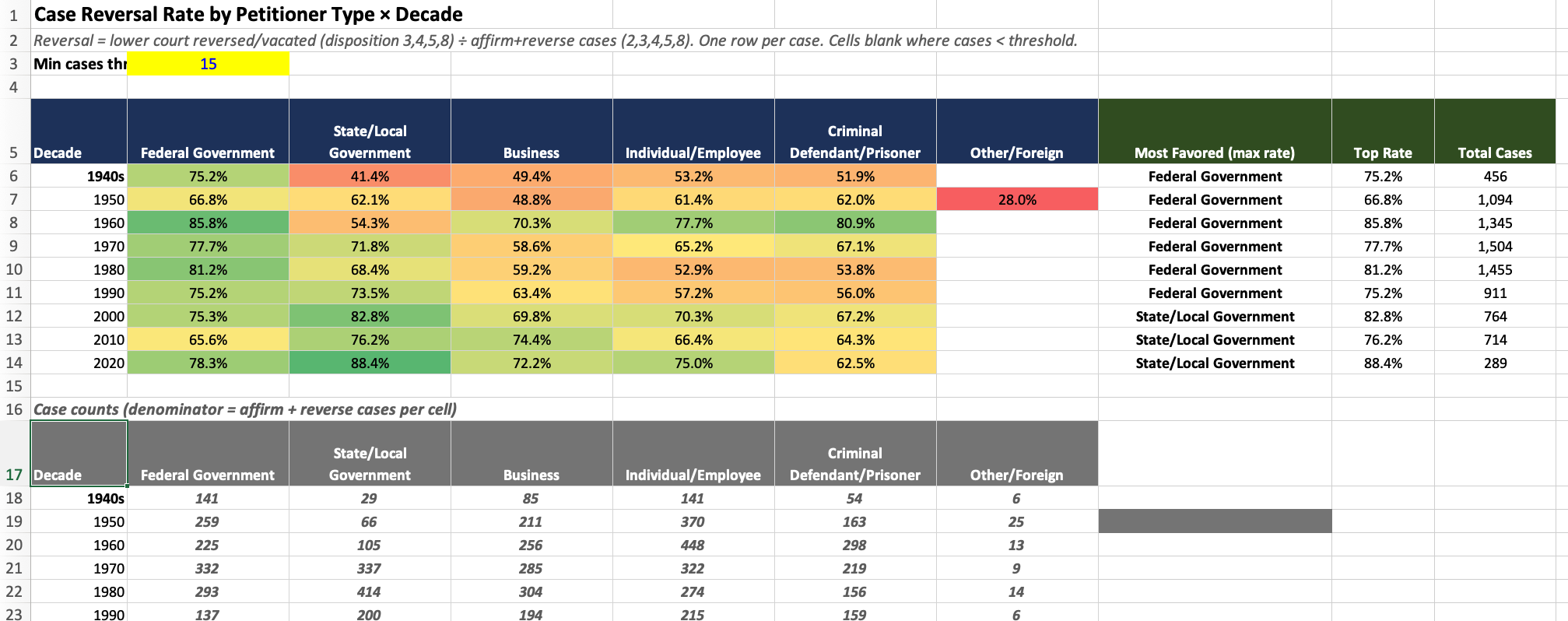
Outputs
For those who want to see the entire transcript of my conversation with Claude for Excel (warts and all, including a wrestling match over frozen panes) and the final Excel sheet, they are available below.
I also had Claude Cowork write a tiny program to convert the .json format of the transcript into something more visually appealing. The resulting .html file is below, along with a screen capture.
Conclusion
Return to that law professor staring at a spreadsheet that just sits there. The wall that kept those numbers locked away was never really about the data; it was about fear — fear of the formulas, the statistics, the technical apparatus that seemed to belong to someone else. What this experiment shows is that the wall is far lower than it looks. Sorting, pivot tables, regressions, even a p-value correction I had never heard of—all reached by asking questions in plain English inside a tool most lawyers already own and have at least occasionally used.
The same plain-English approach reaches much further than Excel. You can interrogate far larger datasets with SQL against a sqlite database. You can run Python for analysis Excel will never touch. And you can hook Claude up to Wolfram, handing the symbolic mathematics and real-time curated knowledge—exact integrals and regressions, number theory, live scientific and financial data—to the ultimate computer-algebra engine that computes precisely rather than estimates. The language of instruction stays the same: English. What changes is only the reach.
So be unafraid, be very unafraid. The spreadsheet is not a mysterious technical object. With AI alongside, it becomes a practical and familiar home from which to start asking empirical questions. Your data awaits.
Notes
- I keep saying "English." But what I mean really is human language. I don't know how many languages Claude for Excel understands, but it does understand Spanish and French.
- Just as large language models can hallucinate when it comes to more typical legal tasks, so too with data analysis. Before using these analyses for mission critical work or for submissions to the Court, they need to be checked and doublechecked. Some of that can be done by other large language models. Others can be done by plausibility checking and spot checking. More serious work likely needs to be checked by a human expert, who may want to run alternative software on the data.
- Way back in the almost-forgotten days of October 2025, I wrote an earlier post on data analysis with Excel and Google Sheets. Although that post was fine for its time, much has changed, most notably the ability to work inside of Excel and yet have Claude know all about your spreadsheet.