
No, AI isn't ruining student writing
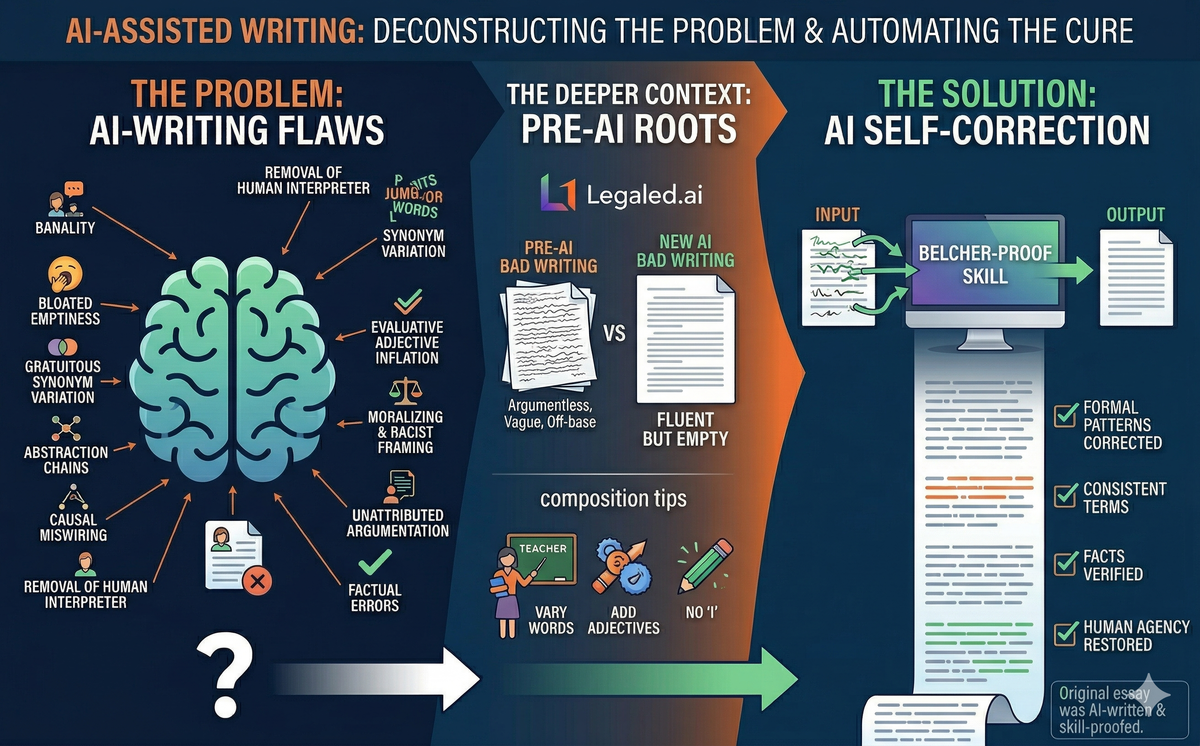
In September 2025, Wendy Laura Belcher — professor of African literature at Princeton and author of the widely adopted Writing Your Journal Article in Twelve Weeks — published "10 Ways AI Is Ruining Your Students' Writing" in The Chronicle of Higher Education. The article catalogues ten recurring defects in AI-assisted student prose: banality, bloated emptiness, gratuitous synonym variation, abstraction chains, causal miswiring, removal of the human interpreter, evaluative adjective inflation, moralizing and racist framing, unattributed argumentation, and factual errors.
Belcher's taxonomy is useful — more useful than most writing advice — because it names specific, recurring patterns rather than gesturing at vague qualities. Her examples are hard to argue with. A sentence like "Africa is home to some of the world's most diverse literary works" is, as she shows, grammatically correct and semantically vacant. AI told a student that Things Fall Apart was "translated into English" when Achebe wrote it in English. A student paper moralized about Igbo practices as "failures to meet Western ethical standards." These are real problems.
But Belcher's framing — that AI is ruining student writing — rests on an assumption she never examines. And when you build a tool to fix the very flaws she identifies, the tool works. AI can fix the human writing flaws that AI replicates. (For those disinclined to read further, here's the AI skill file that Belcher-proofs your prose).
Belcher's Unexamined Counterfactual
The word "ruining" implies a prior state worth preserving. Belcher's own evidence undermines this. She writes: "I never used to receive essays with banal arguments. I would get papers with no argument, or vague arguments, or totally off-base arguments, but never banal ones." A paper with no argument is worse than a paper with a banal one. A paper that is "totally off-base" has failed more fundamentally than one that states the obvious. The pre-AI baseline Belcher describes — argumentless, vague, off-base — was not good writing. It was a different flavor of bad.
My own experience undermines the premise too. Having taught at a good law school for over three decades, I watched student writing decline prior to the large language model revolution — not because students are less capable, but because they arrive with less training. Writing instruction takes enormous time, and fewer teachers at the high school and undergraduate level have that time to give. Students read less, and what they do read is less likely to be the kind of careful, long-form, well-constructed prose that teaches by example. The result is that by the time students reach professional school, many of them still write poorly. That was true before AI and it remains true with AI. You cannot "ruin" what was already in serious trouble. AI has changed the character of bad student writing — from incoherent and ungrammatical to fluent-but-empty — but the underlying problem is not a technology. It is a decades-long erosion of the teaching and reading that produce good writers.
In short, what AI has done is change the kind of failure. Students used to fail by writing incoherently; now they fail by "writing" fluently but emptily. Belcher is right that the new failure mode is insidious — it looks competent and can fool a tired grader — and she never exactly argues that the old failure mode was preferable. She implies it, by framing everything as degradation from a prior state, but the prior state she describes was also terrible.
The Pedagogical Roots of "AI Writing"
There is a related issue Belcher doesn't emphasize sufficiently. Many of the flaws she catalogues are things that composition pedagogy actively teaches.
She acknowledges this for her Flaw 3 (synonym variation): "This terrible advice about varying words is regularly given in composition classes, especially at the middle- and high-school levels." But she doesn't follow the thread. Consider how thoroughly American writing instruction drills these habits into students before they reach college:
Synonym variation. From middle school onward, students are taught never to repeat a word. Use "the protagonist" once, then switch to "the central figure," then "the main character." This is Belcher's Flaw 3 — and students were doing it before ChatGPT existed.
Adjective inflation. "Use vivid, descriptive language!" is standard writing-class advice. Students learn to modify every noun: the "compelling" narrative, the "profound" insight, the "nuanced" exploration. This is Belcher's Flaw 7.
Removing the interpreter. Students are told never to use "I" in academic writing. The result is exactly what Belcher describes as Flaw 6: the text becomes the agent of every verb. "The novel subverts" because the student has been forbidden from writing "I argue that the novel's X is undercut by its Y."
The "not X, but Y" construction. This is a staple of the five-paragraph essay template taught in high schools across the country.
If students arrive at Princeton having been taught for a decade that good writing means never repeating a word, always inserting a modifier before a noun, and never using "I" in an essay, how much of what Belcher calls "AI writing" is actually the style those students were going to produce anyway, just faster? AI didn't invent these habits. It was trained on text produced by the same pedagogical tradition that shaped the students Belcher is trying to rescue. If AI fails to meet Belcher's standards, it is largely because the human writing on which it was trained does not meet them either.
The Legal Writing Problem: Where Synonym Variation Can Be Malpractice
Belcher writes about literary analysis, but her Flaw 3 — gratuitous synonym variation — has a sharper edge in legal writing, where it is not merely a stylistic annoyance but a source of real harm.
The late Tina Stark, who taught transactional drafting at Fordham and then at Emory — where she founded the Center for Transactional Law and Practice — and wrote the brilliant Drafting Contracts: How and Why Lawyers Do What They Do, formulated a rule that every transactional lawyer learns (or should): never change the wording unless you intend to change the meaning. In contract drafting, if you call something a "termination" in one clause and a "cancellation" in the next, you have invited the argument that you meant two different things. Courts will assume the drafter chose different words for a reason. Synonym variation, which Belcher treats as a readability problem, becomes in legal drafting a drafting defect — one that can shift rights, create ambiguity, and generate litigation.
One might expect AI to do this constantly in contract drafting — to cycle through "shall," "will," "must," and "agrees to" as if they were interchangeable, or to call the same party "the Licensee," "the receiving party," and "the end user" within a single section. I tested this. It turns out that modern AI models are actually quite good at maintaining term consistency in contracts, probably because the legal drafting in their training data is itself highly disciplined. When I asked a model to draft a software license agreement — both with and without a formal definitions section — it used "shall" as the obligation verb throughout, kept party labels consistent, and never cycled defined terms. The training data for contract drafting, unlike the training data for literary essays, happens to teach the right behavior.
Where the problem does appear — in a subtler form — is in less structured legal writing. I tested this too: I asked an AI to draft a brief arguing rational basis review, a memo on non-compete enforceability, and a law review section on the major questions doctrine. The core legal terms stayed consistent — "Equal Protection Clause" was always "Equal Protection Clause," "major questions doctrine" appeared ten times without variation. But the thing being analyzed got re-labeled freely. In the brief, the challenged regulation was also called "the restriction," "the prohibition," "the requirement," "the buffer zone," and "the challenged regulation" — six labels for one ordinance. The memo switched between "non-compete agreement," "non-compete covenant," "non-compete provisions," and "restrictive covenant" for the same clause, and toggled between "choice-of-law provision" and "choice-of-law clause." The brief alternated between "rational basis test" and "rational basis review."
None of this is as bad as calling Okonkwo "the protagonist," "the central figure," and "the key player" in three consecutive sentences. But in legal writing, even moderate variation carries costs. Switching between "the regulation" and "the restriction" in a brief is not ambiguity in the contractual sense, but it signals to the court that the writer may not be in full control of the material. A brief that picks one label and sticks with it reads as disciplined. One that cycles labels reads as if its author — or its AI — is prioritizing sentence-level variety over document-level coherence.
What makes the legal context different from Belcher's literary-analysis context is that some law students have actually been taught the right rule. Stark's principle — same meaning, same words; different words, different meaning — is standard in transactional drafting courses. But many law students never take a transactional drafting course, and those who learn the rule in one context may not apply it when writing briefs, memos, or seminar papers. AI, meanwhile, handles formal contract drafting well on this dimension (the definitions section and standard-form architecture seem to anchor it), but exhibits moderate Flaw 3 in less structured legal prose — the kind of prose where students are most likely to use AI assistance.
After observing these patterns, I modified the Belcher-proof skill so that it now detects whether the document is legal in nature and adjusts its Flaw 3 repair strategy accordingly. For contracts and other operative legal instruments, the skill applies the Stark rule: identify the legally operative term and use it everywhere the same meaning is intended, flagging any variation as a potential change in legal effect. For briefs and memos, it targets the specific pattern I observed — leaving core doctrinal terms alone but collapsing the descriptive labels for the subject of analysis into one consistent term. The skill distinguishes between contexts where variation is merely ugly (a law review article) and contexts where it is dangerous (a contract, a statute, a set of jury instructions).
The broader point is that Belcher's taxonomy is extensible. Her ten flaws were identified in the context of literary analysis, but the underlying patterns appear across disciplines, sometimes with different stakes. I adapted the skill for legal writing because that is our domain. Others could do the same for their own: a scientist might add detection for AI's tendency to insert hedging language that weakens empirical claims, or a philosopher might add checks for the kind of false precision that AI brings to definitions. The checklist is a framework, not a fixed list.
The Skill That Proves the Point
I decided to test whether AI could fix its own characteristic flaws. Using Belcher's taxonomy as a blueprint, I built a "Belcher-proof" editing skill — a structured instruction set that tells an AI model to detect and repair each of the ten flaws, iterating through a document until a verification pass comes back clean.
Under my loose direction, AI wrote three test essays, each deliberately loaded with Belcher flaws: a paper on Achebe's Things Fall Apart (containing a factual error about translation, synonym cycling for Okonkwo, moralizing about Igbo practices, text-as-agent constructions, and abstraction chains), a paper on Soyinka's Death and the King's Horseman (with a wrong adjective, a misused literary term, a potentially plagiarized coinage, and Western-centric moralizing), and a paper on Oyono's Une Vie de Boy (with a fabricated biographical claim, derivative argumentation, and windbag phrasing).
I ran each essay through the same AI model twice — once with the Belcher-proof skill, once without it. The results:
With the skill: 22 out of 22 assertions passed. Every factual error corrected. Every synonym chain collapsed to consistent naming. Every text-as-agent construction rewritten. Every moralizing passage replaced with analytical observation. Every abstraction chain unpacked into concrete prose. Every evaluative adjective either deleted or replaced with specific description.
Without the skill: 4 out of 22 assertions passed. The model retained "Africa is home to some of the world's most diverse literary traditions." It kept "rich tapestry." It still had the novel "subverting" and "exposing" as a conscious agent. It still moralized about Igbo "ethical blind spots."
The difference between 100% and 18% was not a different model, different training data, or different computational resources. It was a 400-line instruction set — Belcher's own taxonomy, operationalized.
Then I Ate My Own Dog Food
To make sure the skill wasn't just good at fixing other people's writing, I ran it on earlier drafts of this very blog entry that AI had produced — prose that was not literary analysis but informal academic writing about pedagogy and AI.
The skill flagged twelve instances of Belcher flaws in our own text. Five cases of adjective inflation ("genuinely," "deep," "excellent," "deeper," "honest approach"). Two causation misfires ("tendencies that produce the original slop can creep" — tendencies don't creep; "inherited those pathologies" — AI doesn't inherit, it was trained on). One fabricated statistic ("80–90%," presented as a number but actually a guess). One windbag flourish ("golden age of undergraduate prose"). One anti-human construction ("the skill guards against this" — the skill doesn't guard; it's a document). One abstraction-chain closing ("the unexamined assumption at the heart of the piece").
All twelve were fixable. The revised text said the same things more precisely. The fabricated statistic was replaced with a hedged claim. The causal verbs were corrected. The evaluative adjectives were deleted. A verification pass confirmed no new flaws had been introduced.
What This Means
The test results complicate Belcher's narrative in three ways.
First, the flaws are generally formal, so the fixes are tractable. Belcher's ten defects are structural patterns — synonym cycling, abstraction chains, text-as-agent constructions, adjective inflation. The moment you name a pattern precisely enough to teach a student to avoid it, you've named it precisely enough for an AI to detect and repair it. Belcher built the diagnostic; I just automated it.
Second, the skill mirrors what good teaching does. Belcher's article is, functionally, a lecture. She tells students: here are ten things wrong with your AI-assisted prose, now rewrite without them. She reports that this process has value — "students will learn something through this process." The skill does the same thing, except it delivers the lecture to the model instead of to the student. If telling a student "don't use three different labels for the same character" improves student writing, telling a model the same instruction improves model output, for the same reason: the problem was not inability but unawareness. The model cycles synonyms because its repetition penalty pushes it to, not because it cannot use a consistent term. Name the problem and it stops.
Third, the skill works precisely because Belcher's claim that AI "cannot actually think" and "can only string together predictable words and phrases" is overstated. If the model could only string together predictable words, it could not follow a meta-instruction that tells it to do the opposite of what's predictable: to delete rather than elaborate, to prefer specificity over generality, to flag its own outputs as suspect. The model can follow a counter-instruction that overrides its default tendencies. That capacity — call it directed self-correction — is enough to fix most of the problems Belcher identified.
The Hard Cases
The skill handles Flaws 1 through 7 well because those flaws are formal and their repairs are well-defined. But three of Belcher's flaws resist automation.
Flaw 8 (racism and moralizing) requires recognizing when a passage imposes Western norms on non-Western subjects. The skill catches obvious markers — "Western ethical standards," "internalizing helplessness" — but may miss subtler colonial framings. This flaw demands cultural knowledge that varies by text and context.
Flaw 9 (plagiarism) cannot be fixed without access to a scholarly database. The skill flags suspicious passages — a student claiming credit for what sounds like an established scholarly argument — but it cannot verify the source. It handles this by flagging rather than "fixing," which avoids laundering borrowed arguments into paraphrases.
Flaw 10 (factual errors) depends on whether the model's training data contains the correct information. The test runs caught that Achebe wrote in English and that Oyono wrote in French. But the model could miss an obscure biographical detail about a less-canonical author. The skill flags unverifiable claims for human review rather than silently guessing.
These are the flaws where Belcher's critique bites hardest, because they are the ones where AI's failures can do real intellectual harm — producing prose that is not just ugly but racist, plagiarized, or false. The skill reduces the noise so a human reviewer can focus on these problems. It does not eliminate the need for that reviewer. Indeed, earlier drafts of this blog entry contained factual errors that its human director (me) was perceptive enough to identify and correct.
The Real Question
None of this means Belcher's taxonomy is wrong. It works. It names specific patterns, gives concrete examples, and tells you what to do about each one. That is more than most writing advice manages. And our own experiments confirm that raw AI output can exhibit various writing flaws. Her work is a goldmine for people predisposed to hate AI.
But the question her article raises is not the one she thinks she is answering. The question is not "Is AI ruining student writing?" The question is: "Were we teaching students to write well in the first place?" If the flaws AI produces are the same flaws that composition pedagogy has been instilling for decades — if synonym variation, adjective inflation, and the banishment of "I" are taught in middle school and reinforced through high school — then AI is not the cause of bad student writing. It is a tool that accelerates and reveals pre-existing pedagogical failures.
And if AI can also fix those failures, once someone takes the trouble to name them precisely, then the case against AI is weaker than Belcher suggests. People have been writing down what good prose looks like for a long time — Strunk's Elements of Style dates to 1918, and Bryan Garner has been cataloguing legal-writing pathologies for decades. What Belcher adds is not the first description of good writing but a specific, checkable list of the patterns AI emulates and amplifies — a list concrete enough that AI itself can be instructed to detect and eliminate each item on it. That is a real contribution, even if Belcher overstates it as a case against AI rather than a case against the pedagogical habits AI has learned to mimic. The checklist she wrote is the kind of thing a machine can act on. And when the machine acts on it, the prose improves.
Note
About 90% of this essay was written by AI and run through the "Belcher-Proof" skill. It took about six prompts to get it to its present state. And it didn't take 12 weeks. It took about two hours in total. Does it exhibit the flaws Belcher identifies? Not many, I think.