
EarDraft: Use AI to create language made to be heard

Most prose is written to be read by the eyes, not heard by the ears. The difference matters. Syntax that glides across a page can stumble when voiced; sentences that feel rich in writing can sound pompous aloud. That gap—between text that looks good and text that sounds good—is where a new class of AI tools ought to intervene. What we need is an app that takes written prose—especially the kind produced by large language models—and reshapes it for listening. The goal is not to dumb it down or make it “folksy.” It is to adapt rhythm, pacing, and clarity so that the listener’s brain, which can’t skim or reread, remains fully engaged. Written prose leans on structure and visual cues; spoken prose relies on cadence, repetition, and subtle signposting of transitions. The app would have to understand both modes deeply.
Technically, you might be able to get the desired results using some prompt engineering. Upload the text, tell the AI to produce something that sounds better when heard, and hope for the best. Or you could regularize that process by constructing a CustomGPT, Gemini Gem, a Claude project or similar templated prompt. For best results, however, you will do better with a Claude skill or standalone app. That's because converting text to be read into text to be heard is a complex process that requires some thought and possibly multiple passes through the text. The system needs to think about rhythm differently, reiterate theses every couple of paragraphs, use enumeration more frequently but not to excess, and undertake dozens of other transformations that convert prose perfectly suited for reading into prose better suited to be heard. Converting text to listenable language is not merely a formatting step; it is a recomposition of the material for a different cognitive channel.
AI both increases the need for such a tool and increases the possibility of its fabrication. It increases the need because, for better or worse, it greatly increases the volume of prose that can be produced. Indeed, there is a growing legal industry designed to produce just such prose. It's often not possible, however, to absorb the torrent of information AI produces. One of the ways to force the wisdom of AI into one's head, however, is to hear it. Doing so is definitely slower: many read twice as fast as they hear. But at least for many people (including this auditory learner) it works much better. Fortunately, AI can come to the rescue in creating a better channel into the human brain be it housed in the mind of a law student, a law professor, a senior partner, or a juror in an important case. What we end up with today would not have put Edward Bennett Williams, John Kennedy's Ted Sorenson or Ronald Reagan's Peggy Noonan out of a job. But as a foundation for decent run-of-the-mill spoken word output, 2025 AI can do a good job.
EarDraft: The Skill and the App
So much for the buildup. Let's take a look at the product. If you have a paid version of Claude, here's a link to the skill you want to upload and enable. If you do not, however, here's a link to an app that does much the same thing and that was produced, as has been the case with other apps described on this blog, by laying a foundation with the Skill2App Skill with which I have endowed Claude and perfecting the result using AI vibe coding assistants like Claude Code. Precisely because it reaches a broader audience, I'm going to focus for the remainder of this blog entry on the app.
Here's a screen capture of it in action.
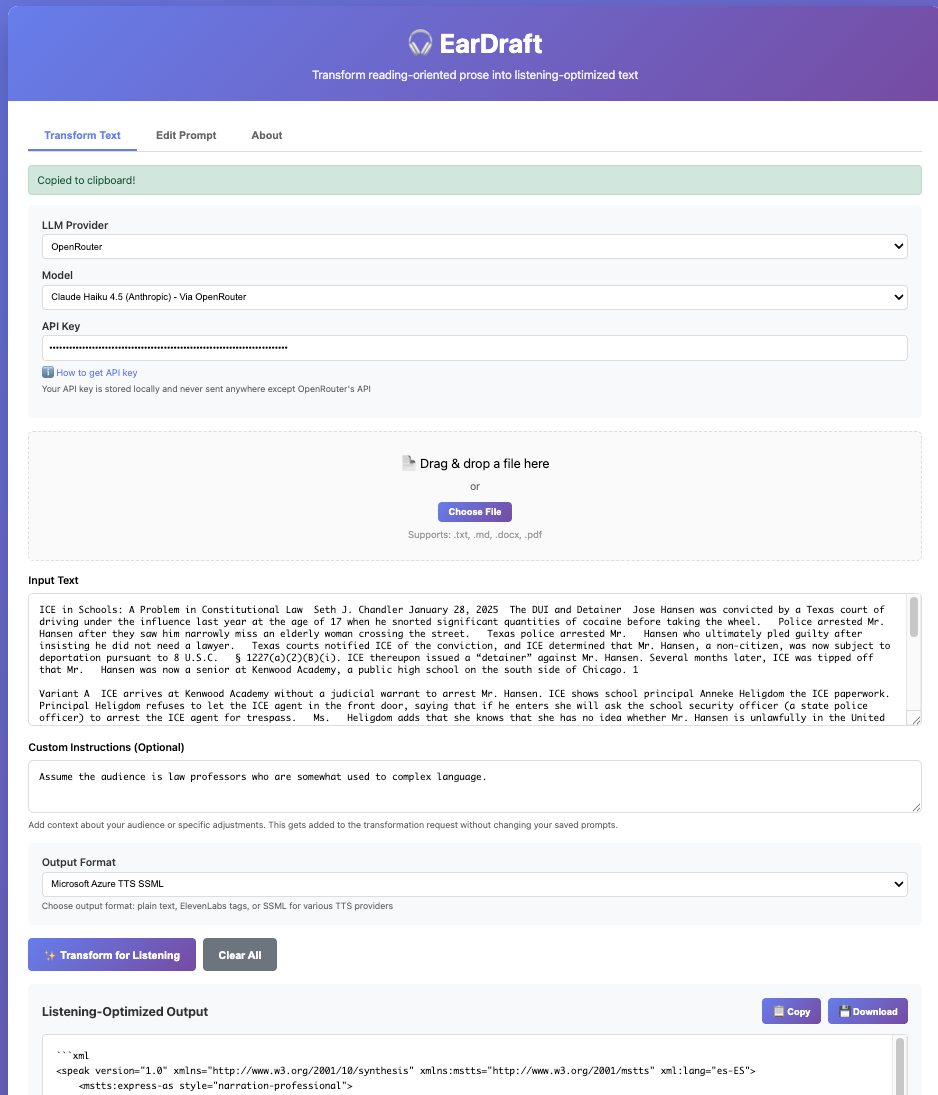
And here's how the app works.
Getting Started
First, select your AI Provider from the dropdown (OpenAI, Anthropic, Google, or OpenRouter. Enter your API key for that provider in the text field below. Your key is stored locally in your browser—never sent anywhere except directly to your chosen AI provider.
Choose your AI Model from the available options. Depending on which provider you selected, you'll see the latest models from OpenAI (ChatGPT5 variants), Anthropic (Claude 4.5 Sonnet and Haiku and the pricey Opus 4.1), Gemini (the 2.5 variants), or OpenRouter, which gives you access to models from multiple providers.
Setting Your Language and Output Format
The Language dropdown determines which transformation guidelines the AI follows. Each language (English, French, Spanish, Italian, German, Portuguese) has culturally-specific instructions for natural spoken rhythm and discourse patterns.
The Output Format selector controls how the transformed text is delivered:
- Plain text [default] - Standard prose without markup. Unless you are pretty sure you want to give the output to a particular text to speech AI, you should stick with this choice.
- ElevenLabs (with tags) - Includes [pause:medium] and [emphasis] tags for precise TTS control
- ElevenLabs (implicit) - Uses punctuation and structure to guide natural pacing
- SSML formats - XML markup for Amazon Polly, Google Cloud TTS, or Azure TTS platforms
Adding Your Content
Paste text directly into the input area, or drag and drop files (.txt, .md, .docx, .pdf). The app extracts text automatically.
Use Custom Instructions to provide audience context: "Assume the audience is 12 years old" or "This is for medical professionals." Or, if you created a particular style, as I described in an earlier blog entry, use some variant of that. These instructions help the AI adjust tone and complexity appropriately.
Transformation and Advanced Features
Click Transform for Listening to process your text. The transformed output appears below once it has been completed.
The System Prompt section at the bottom shows the complete transformation guidelines being used. You can edit these instructions, save them as markdown files, load custom prompts, or reset to defaults for experimentation.
I've added two experimental features. The first is to make it multilingual. Spoken Portuguese may not have the same customs when it comes to spoken word information transfer as does English. I've thus added default prompts for Spanish, French, German, Portuguese, which were the languages about which ChatGPT felt knowledgeable enough to opine.
The second experiment is to let the user direct the AI to produce a script for other AIs. Now the inflection subtleties we generally leave to human actors such as whispering, pausing, or depicting sarcasm are spelled out in forms favored by various text-to-speech software. Thus you can direct the ElevenLabs format in which we might see things like this:
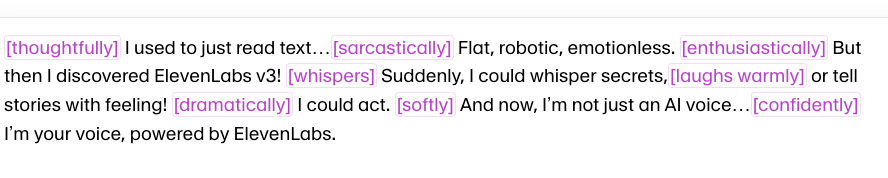
Or we have the SSML form favored by Amazon Polly and other apps that might look like this:
[emphasis] Variant A.
ICE arrives at Kenwood Academy without a judicial warrant to arrest Mr. Hansen. [pause:short] They show Principal Anneke Heligdom the ICE paperwork. Principal Heligdom refuses them entry. [pause:short] She states that if the agent enters, she will ask the school security officer—who is a state police officer—to arrest the ICE agent for trespass. Ms. Heligdom adds that she has no idea whether Mr. Hansen is unlawfully in the United States. [pause:short] She says, "He told me that, but I have no idea whether it's true. Neither he nor I are immigration attorneys."We can combine non-English languages with non-standard forms and get output like this
```xml
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" xml:lang="es-ES">
<mstts:express-as style="narration-professional">
<p>
<prosody rate="slow">
<emphasis level="strong">ICE en las Escuelas: Un Problema en Derecho Constitucional.</emphasis>
<break time="500ms"/> Por Seth J. Chandler. <break time="200ms"/> 28 de enero de 2025.
</prosody>
</p>
<p>
<emphasis level="strong">El DUI y la Orden de Detención.</emphasis>
<break time="500ms"/> José Hansen fue condenado el año pasado por un tribunal de Texas por conducir bajo la influencia, a la edad de diecisiete años. Esto ocurrió después de que inhalara una cantidad significativa de cocaína antes de tomar el volante.
<break time="800ms"/> La policía arrestó al señor Hansen tras verlo casi atropellar a una mujer mayor que cruzaba la calle.
<break time="500ms"/> Las autoridades de Texas lo detuvieron, y él finalmente se declaró culpable, insistiendo en que no necesitaba un abogado.
...
<emphasis level="strong">Su Asignación.</emphasis>
<break time="500ms"/> Asuma que ha sido designado para representar a la señora Heligdom.
<break time="800ms"/> ¿Qué defensa constitucional ofrecería?
<break time="800ms"/> ¿Cómo cree que su defensa se desarrollaría bajo las Variantes A, B y C?
</p>
</mstts:express-as>
</speak>
```If the desired end product is a script for a human voice actor such as yourself (rather than an AI text-to-speech engine), just leave the setting at its default value.
An Example
Let's see the app in action. I start with a report generated from a NotebookLM notebook. I deliberately selected one of the driest topics known to law: operation of the Medicare Access and CHIP Reauthorization Act (MACRA). Here are excerpts of the prose produced by the AI. There's nothing really wrong with it. It's an accurate recounting of an extremely important subject that, at first glance, is extremely dull.
4. Challenges and Criticisms of MIPS
As a future administrator, it is essential to understand not just the mechanics of MIPS, but also its well-documented limitations. The program has been controversial since its inception, and provider organizations continue to highlight major flaws that undermine its intended goals.
• Administrative Burden: A primary complaint is the sheer complexity and administrative workload of MIPS. Surveys have found that the vast majority of providers consider the program "very or extremely burdensome." Many physicians report that the time and resources required for data collection and reporting divert staff focus away from patient care and toward data entry.
• Impact on Small and Rural Practices: The resource-intensive nature of MIPS disproportionately affects small, independent, and rural practices. These practices often lack the dedicated staff, financial resources, and technological infrastructure to comply with the complex reporting requirements. As a result, they consistently score lower than larger, well-resourced health systems, putting them at greater risk for financial penalties. This pressure has accelerated market consolidation, as struggling independent practices are forced to sell to larger systems to survive.Let's now feed that to my Claude Skill. Here's the prompt I provided.
Use your Eardraft Skill to convert this to prose designed to be heard. %%% [MACRA essay included here] The topic is very technical so make it lively but without folksy devices. You can try to use my blog voice to guide you but the main focus should be on using the Eardraft skill. [Blog voice material attached]
Here's how that original passage now reads:
As a future administrator, you need to understand not just the mechanics of MIPS, but also its well-documented limitations. The program has been controversial since its inception, and provider organizations continue to highlight major flaws that undermine its intended goals.
The primary complaint is the sheer complexity and administrative workload of MIPS. Surveys have found that the vast majority of providers consider the program very or extremely burdensome. Many physicians report that the time and resources required for data collection and reporting divert staff focus away from patient care and toward data entry.
The resource-intensive nature of MIPS disproportionately affects small, independent, and rural practices. These practices often lack the dedicated staff, financial resources, and technological infrastructure to comply with the complex reporting requirements. As a result, they consistently score lower than larger, well-resourced health systems, putting them at greater risk for financial penalties. This pressure has accelerated market consolidation. Struggling independent practices are being forced to sell to larger systems to survive.It's not hugely different – which is a good thing – but there are subtle changes that should improve its delivery. For example, the original said: "This pressure has accelerated market consolidation, as struggling independent practices are forced to sell..." The revised version says. As Claude explains:
The original uses a subordinating conjunction ("as") that creates a long, complex sentence. For listening comprehension, I broke this into two sentences. The period creates a natural pause that helps listeners process the causal relationship without getting lost in syntax. I also changed "are forced" to "are being forced" to maintain present-tense continuity and active voice rhythm.
You can compare the original with the revised version on your own time, but I think you will find that Claude has done a fine job negotiating the fine line between wholesale change of a technical document and leaving it in a form where oral comprehension would be challenging.
Now let's give the same document to the app with the same prompt. Here's the same passage rendered by the app.
## Challenges and Criticisms of MIPS
As a future administrator, you need to understand not just the mechanics of MIPS, but also its well-documented limitations. The program has been controversial since its inception. Provider organizations continue to highlight major flaws that undermine its intended goals.
First, the administrative burden. A primary complaint is the sheer complexity and administrative workload of MIPS. Surveys have found that the vast majority of providers consider the program very or extremely burdensome. Many physicians report that the time and resources required for data collection and reporting divert staff focus away from patient care and toward data entry.
Second, the impact on small and rural practices. The resource-intensive nature of MIPS disproportionately affects small, independent, and rural practices. These practices often lack the dedicated staff, financial resources, and technological infrastructure to comply with the complex reporting requirements. As a result, they consistently score lower than larger, well-resourced health systems, putting them at greater risk for financial penalties. This pressure has accelerated market consolidation, as struggling independent practices are forced to sell to larger systems to survive.Both Claude and I agree that the EarDraft App did a little better than did the EarDraft Skill. Here's why
The explicit "First," and "Second," signposting is genuinely helpful for listeners. This is a technical passage covering multiple distinct criticisms, and oral enumeration helps listeners organize the information in real-time. The Claude Skill under-weighted this principle— it focused on natural flow but sacrificed structural clarity.
The Claude Skill version assumes listeners will track the conceptual shifts through topic sentences alone ("The primary complaint is..." then "The resource-intensive nature..."). But the App makes the structure impossible to miss, which is exactly what listening optimization should do.
The app also shows better pacing with the opening split—two crisp statements that establish the section's critical stance before diving into specifics.
The only place Claude's Skill might defend its choice is the final sentence split, which does make the causal chain slightly easier to process. But reasonable people could differ on that one.
In short, however, both the EarDraft Skill and the EarDraft App converted what would have been a deadly dull report on MACRA into something easier to digest when heard. Using the Skill was free. Using the App with Claude Sonnet 4.5 as the conversion model cost me about 4 cents.
Conclusion
Modern AI is fully capable of producing perfectly respectable prose. Yes, there are too many "game changers" and sycophancy and all the other woes to which AI is heir to. But with some careful prompting or some modest editing you can get rid of them. What AI does not do, however, unless you remember to ask, is to produce prose designed to be spoken aloud and heard. Although neither the Skill nor App described here do a perfect job, both versions of EarDraft get you 90% of the way from prose with a tin ear to language designed to be heard.
Notes
- This project had a very meta trajectory. Like several of the projects I have recently described in this blog, it involved two Claude Skills, one from Anthropic built in to paid Claude (the Skill Building Skill) and one constructed by me (Skill2App) using that very skill. It's a fantastic if somewhat elaborate workflow, in my humble opinion. I started by describing what I wanted to Claude's Skill Building Skill and had it construct a skill that would convert prose designed for reading into prose designed for hearing. That process generates a skill file that one can export, which I did. I then reimported the resulting "EarDraft" skill file back into Claude as a new capability and told the Skill2App skill to create an app whose functionality would match that of the "EarDraft" skill. (Do any readers think this new and useful workflow should be patentable, at least if I file within one year from today?)
The result, as is often the case when using Skill2App, was imperfect. So I then enlisted Claude Code to work on the draft app. As I recognized the shortcomings of the draft app. we collaborated on improving it and adding functionality until, really, it surpassed the capabilities of its Skill progenitor.
I then wanted to restore the Skill to roughly match the capabilities of its child. So I asked Claude Code to describe the app we had constructed. I then fed that description back to the Claude Building Skill and asked it the following:
This is a description of an app. %%% Use your skill building skill to create a skill whose functionality closely mimics that of the app. Obviously you won't have access to language models outside the Anthropic family but that's fine. The anthropic models should be fully capable of doing the trick. Make reasonable assumptions (English, plain text output) about how it all works but let the user prompt you to use special output forms or have special emphases.
The skill you now see and can access here reflects this second round of construction.
- By accident, I had initially asked the app to provide a Spanish language version and turned on ElevenLab markings. Here is the result on the same part of the report.
## Desafíos y críticas de MIPS
Como futuro administrador, es esencial entender no solo la mecánica de MIPS, sino también sus limitaciones bien documentadas. El programa ha sido controvertido desde su inicio, y las organizaciones de proveedores continúan señalando fallas importantes que socavan sus objetivos pretendidos.
[pause:short]
Primero, la [emphasis] carga administrativa. Una queja principal es la complejidad absoluta y la carga de trabajo administrativa de MIPS. Las encuestas han encontrado que la gran mayoría de los proveedores consideran el programa "muy o extremadamente oneroso". Muchos médicos reportan que el tiempo y los recursos requeridos para la recopilación y reporte de datos desvían el enfoque del personal de la atención al paciente hacia la entrada de datos.
[pause:short]
Segundo, el impacto en consultorios pequeños y rurales. La naturaleza intensiva en recursos de MIPS afecta desproporcionadamente a consultorios pequeños, independientes y rurales. Estos consultorios a menudo carecen del personal dedicado, recursos financieros e infraestructura tecnológica para cumplir con los complejos requisitos de reporte. Como resultado, consistentemente obtienen puntuaciones más bajas que los sistemas de salud más grandes y con más recursos, poniéndolos en mayor riesgo de penalizaciones financieras. Esta presión ha acelerado la consolidación del mercado, ya que los consultorios independientes en dificultades se ven obligados a vender a sistemas más grandes para sobrevivir.My Spanish is not nearly good enough to evaluate the quality of the result, but readers fluent in that language can let me know in the comments. You can see, however, that the output did appropriately rely on sentence fragments and include pause markings (in English) that might improve AI delivery.
- Some disciplines such as philosophy apparently still cling to the ancient ritual of reading papers word-for-word, as though the printed page were holy writ and the audience mere witnesses to its revelation. If that’s your faith, feel free to ignore this post, at least until you get tenure. But honestly—why? Reading aloud what everyone could have read in silence is a triumph of form over sense. Listeners aren’t printers; they’re human beings with ears, eyes, and attention spans. Write beautifully, yes—but when you speak, speak. Academia will survive the shock of a presenter who actually engages an audience rather than recites to it.